Fighting the Amnesia Tax: The Hidden Cost of Open-Weight LLM Serving


Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
A recent piece making the rounds, Sumit Pandey on Claude Opus 4.8 versus DeepSeek V4-Pro, landed on a conclusion most of the industry has been circling for six months. The open-weight tier has caught up. DeepSeek V4-Pro posts 80.6% on SWE-bench Verified, ties Gemini 3.1 Pro, and ships under an MIT license. Kimi K2.6 clears 80%. Qwen3.6 Plus is at 78.8%. The decision against the closed frontier is no longer about whether open weights are good enough. For most workloads, they are.
The decision is about whether you can actually capture the savings.
The headline cost gap Pandey draws, DeepSeek V4-Pro at $0.435 / $0.87 per million tokens versus Claude Opus 4.8 at $5 / $25, is real on the API price card. It is not what you will pay in production. The gap between published per-token cost and effective per-request cost is where most open-source AI economics quietly fall apart. Closing it is the entire reason we built Tensormesh.
What the per-token price hides
Every production AI workload has a structural problem the leaderboards never measure. The same context shows up on every request.
A coding agent re-sends the system prompt, the tool definitions, and a chunk of the relevant codebase on each turn. A RAG application re-sends the retrieved documents, often near-identical to the last query, every time the user asks for a follow-up. A document-processing pipeline re-sends the same 200-page contract for every clause it analyzes. A multi-step agent re-feeds its own conversation history on every step of the loop.
Each of those requests, the model processes the same tokens it processed thirty seconds ago. It does the same attention computation. It loads the same intermediate activations. It fills the same KV cache from scratch. On a busy multi-tenant system, that cache is under constant eviction pressure. New user contexts displace older ones, GPU KV memory fills, replicas cycle, so by the time a related request arrives, the entry it would have reused is usually gone.
We call this the Amnesia Tax. It is the single largest line item in most production LLM deployments, and it is invisible in the per-token price.
For high-context workloads (agents, RAG, long-running pipelines) the Amnesia Tax routinely accounts for 60 to 90 percent of compute. The model is doing the same work, on the same tokens, repeatedly. Even if every token costs $0.435 per million, the bill compounds when you are paying to process those tokens forty times in an hour.
DeepSeek themselves price cached input at $0.0036 per million tokens, about 120x cheaper than their own cache-miss rate. That number tells you everything. The vendor knows the marginal cost of reusing a token is near zero. The question is whether you can reuse them in your own infrastructure, on the model you actually want to run.
Why open-source serving makes this worse, not better
The closed APIs have started solving this for you. Anthropic's prompt caching, OpenAI's automatic cache, DeepSeek's cached-input pricing are all attempts to give back some of the Amnesia Tax to customers who would otherwise notice. They work because the vendor controls the entire stack.
When you run open weights yourself, you inherit the problem and lose the solution. You spin up vLLM on a couple of H100s, you point your agent at it, and you watch your GPU utilization graph. What you see is not encouraging. The cards are busy. They are also doing the same work, over and over, for every active session.
This is the gap that quietly kills open-source serving projects. The team migrates from Claude to DeepSeek to capture the 28x output-token savings. Six weeks later, they realize their effective cost per agent-task only fell by 3x, because their workload is context-heavy and their infrastructure has no memory between requests. The price comparison that drove the migration was real on paper and partially fictional in production.
You can fix this, but fixing it is not trivial. Distributed KV-cache sharing across vLLM nodes, eviction policies that survive multi-tenancy, persistence across container restarts, fast cache transfer over the network are all infrastructure problems that have nothing to do with the model. They are the reason a working open-source serving stack takes a team of inference engineers six months to build, and another six to make production-grade.
How Tensormesh removes the Amnesia Tax
Tensormesh Inference is open-weight serving with the Amnesia Tax removed.
You point your OpenAI-compatible client at our endpoint, pick a model from the supported lineup, and ship. The first time a chunk of context shows up (your system prompt, your tool definitions, your retrieved document, your conversation history) we process it and cache the KV state. Every subsequent request that includes that same context reuses the cache. The repeated tokens become free.
Not cheaper. Free. Cached input tokens are $0 on Tensormesh.
Open-weight models you can run today
Serverless, pay-per-token, no setup. Every model below ships with $0 cached-input pricing and works behind an OpenAI-compatible endpoint, including drop-in compatibility with Codex CLI and Claude Code, which is the practical answer to Pandey's "GPT-5.5 still owns the terminal" point. You can run an open-weight coding agent through the same harness, with the cache savings on top.A few notes on the lineup that matter for the open-vs-closed framing.
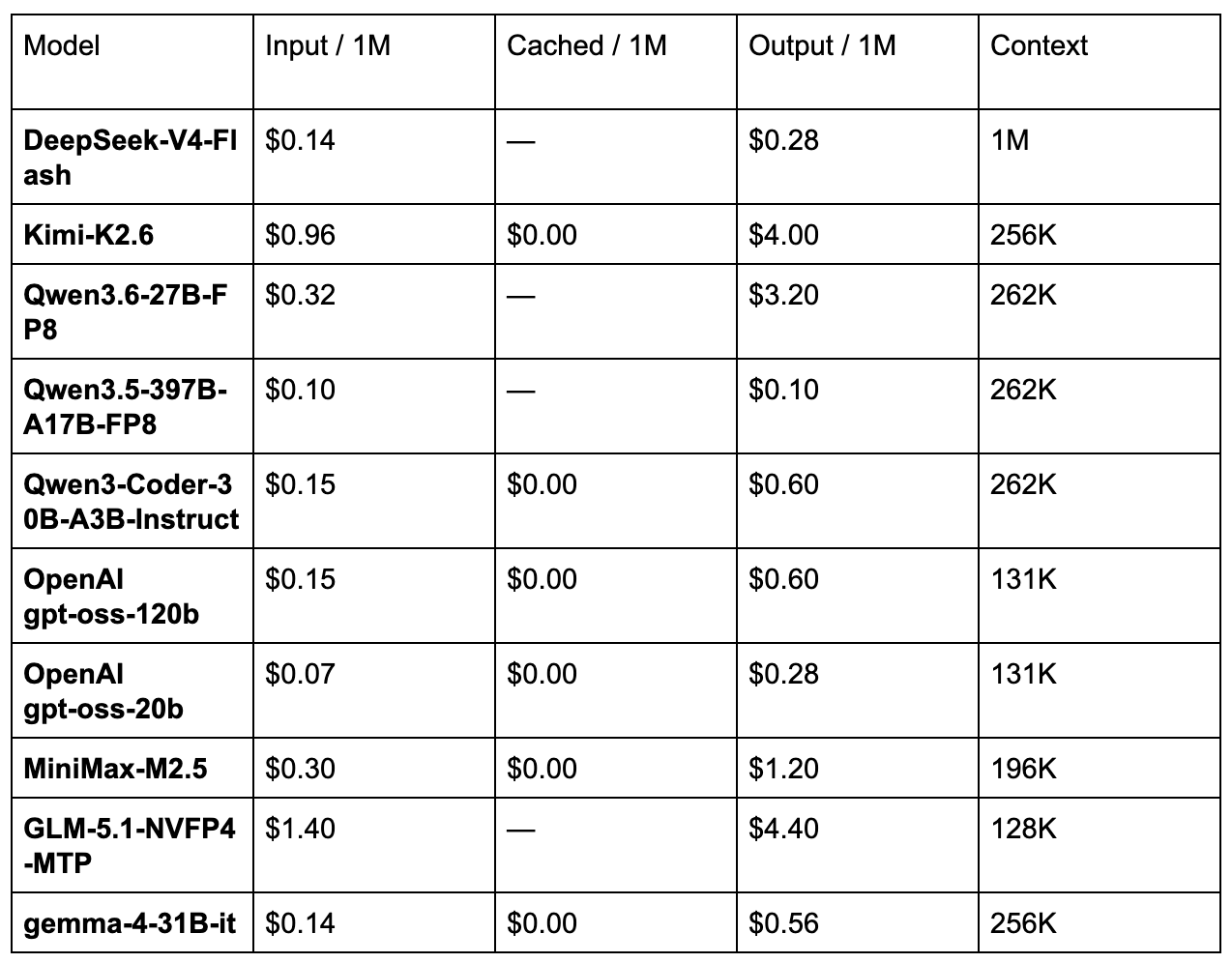
DeepSeek-V4-Flash is the smaller, faster sibling to the V4-Pro that drove Pandey's headline numbers. For most agent workloads, where you want the V4 architecture's reasoning behavior without paying for V4-Pro's full compute envelope, Flash is the practical pick, and at $0.14 / $0.28 it undercuts both V4-Pro's published rate and every closed-frontier API by an order of magnitude.
Qwen3-Coder-30B-A3B-Instruct is the open-weight answer to the "GPT-5.5 owns terminal-bench" argument. Pair it with Codex CLI through our endpoint, cache the system prompt and tool definitions, and you get a coding agent that runs at $0.15 input / $0.60 output with cached context free. The reliability ceiling is lower than GPT-5.5. The cost ceiling is roughly 30x lower.
OpenAI's own gpt-oss release matters here too. gpt-oss-120b at $0.15 / $0.60 is the strongest signal yet that the closed labs are conceding the open-weight tier on cost. If you wanted the same family of training behavior at a fraction of the price, this is now a serverless option.
The engine underneath is LMCache, the open-source KV-cache layer we built and open-sourced. It handles distributed cache sharing across serving nodes, persistence across model instances, intelligent eviction, and fast cache transfer over GDS. Customers integrating LMCache with NVIDIA GPUDirect Storage have reported up to 41x reductions in time-to-first-token on long-context workloads. The same technology powers our hosted serverless platform and, soon, the on-premise Tensormesh Operator for teams that need to run models inside their own perimeter.
Here is what this means for the kind of workload Pandey was writing about.
If you are running a coding agent against an open model, the system prompt and tool definitions hit cache after the first request. Each subsequent turn pays only for the new user input and the new generated output. Effective input cost drops by roughly 60 to 85% on typical agent traces. Our own benchmark reaches 85% cache hit rate on agent skill workloads, and independent evaluations of long-horizon agentic tasks land in the 41 to 80% range across configurations. If you are running RAG on a corpus that gets queried repeatedly, the document chunks hit cache the second time they appear in a prompt. Effective input cost on hot documents trends toward zero.
If you are running long-horizon agents, the exact use case where Pandey argues Opus 4.8's reliability premium is worth paying, you no longer have to choose. You can run an open model with appropriate scaffolding, capture the headline cost savings, and also capture the structural savings from not re-processing your agent's growing context window on every step.
Open weights vs closed frontier
The decision framework Pandey lands on, open weights for cost-sensitive work, closed frontier for long-horizon agents, is correct under one assumption. That serving open weights costs what the published per-token price implies. Once you account for the Amnesia Tax, the math shifts.
A representative agent workload we benchmark internally (coding agent, ~8K-token system context, 20-turn average trace, mid-size open model) looks like this on a naive vLLM deployment versus Tensormesh.
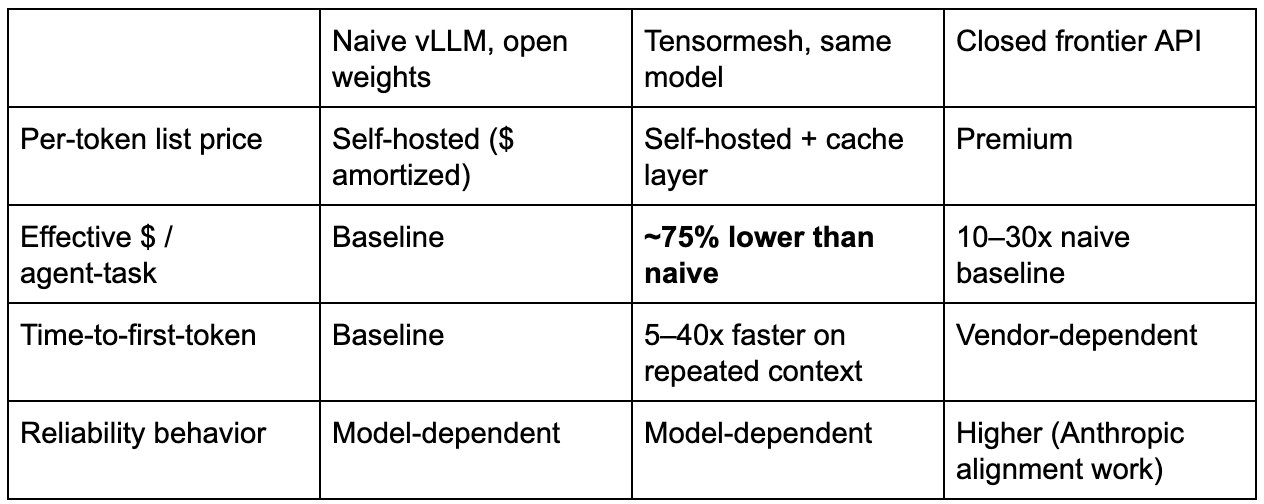
That last row is the one closed-frontier vendors actually earn their premium on, and we are not going to pretend caching solves it. If you need Opus 4.8's reliability behavior in a multi-hour autonomous loop, you pay for Opus 4.8. The case Pandey makes there is correct.
But for the 80% of workloads that are not multi-hour autonomous loops, the agents that need to be reliable for a turn, not for a day; the RAG pipelines; the document processors; the high-volume batch generation, the open-weight tier wins on capability and on cost, if your serving layer captures the savings the per-token price advertises.
The decision, restated
The frontier did not pull away in 2026, it got narrow and specialized. Open weights win for most production workloads. The remaining question is not which model, that has been answered for the majority of use cases. It is whether your serving infrastructure converts the published price advantage into a real one.
Building that infrastructure in-house is six engineers and twelve months. Running on a stack that already delivers this is an API endpoint change.
If you are evaluating open-source serving against a closed-API baseline and the numbers do not quite work, the gap is almost certainly your cache hit rate. Run your workload on Tensormesh for a week. Measure tokens per task and dollars per task, not per-token price. The math gets a lot more honest.
Try Tensormesh and claim your free credits.









































