LMCache's Production-Ready P2P Architecture: Powers Tensormesh's 5-10x Cost Reduction

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
When the founders of LMCache created Tensormesh, they built it on a foundation they knew inside and out. LMCache, the open-source KV caching engine they developed, was designed to solve one of AI inference's most expensive problems. Now, a new collaboration between Tensormesh and Tencent is delivering improvements in LMCache that directly benefit all users as well as our customers through better performance and lower costs.
Why This Matters for Tensormesh Users
LMCache isn't just a component of Tensormesh, it's the engine that makes the platform's 5-10x GPU cost reduction possible. Every improvement to LMCache's architecture means more efficient caching, faster inference, and lower bills for teams running AI workloads at scale.
The latest advancement? Production-grade P2P (peer-to-peer) CPU memory sharing, developed in partnership with Tencent's infrastructure team. This feature eliminates a critical inefficiency that's been costing AI teams millions in wasted compute.
Breaking Down Cache Barriers
Here's the scenario most production deployments face:
A typical setup runs 4 vLLM instances behind a load balancer. Each has 10 GB of CPU cache, 40 GB total capacity. But here's the catch: each request can only use the cache from whichever instance it randomly lands on. That means organizations are effectively getting 10 GB of usable cache per request, not 40 GB.
The result? Duplicated computation, lower cache hit rates, wasted RAM, and ultimately, higher GPU costs as instances repeatedly recompute the same KV states.
Three Approaches to KV Caching: Understanding the Tradeoffs
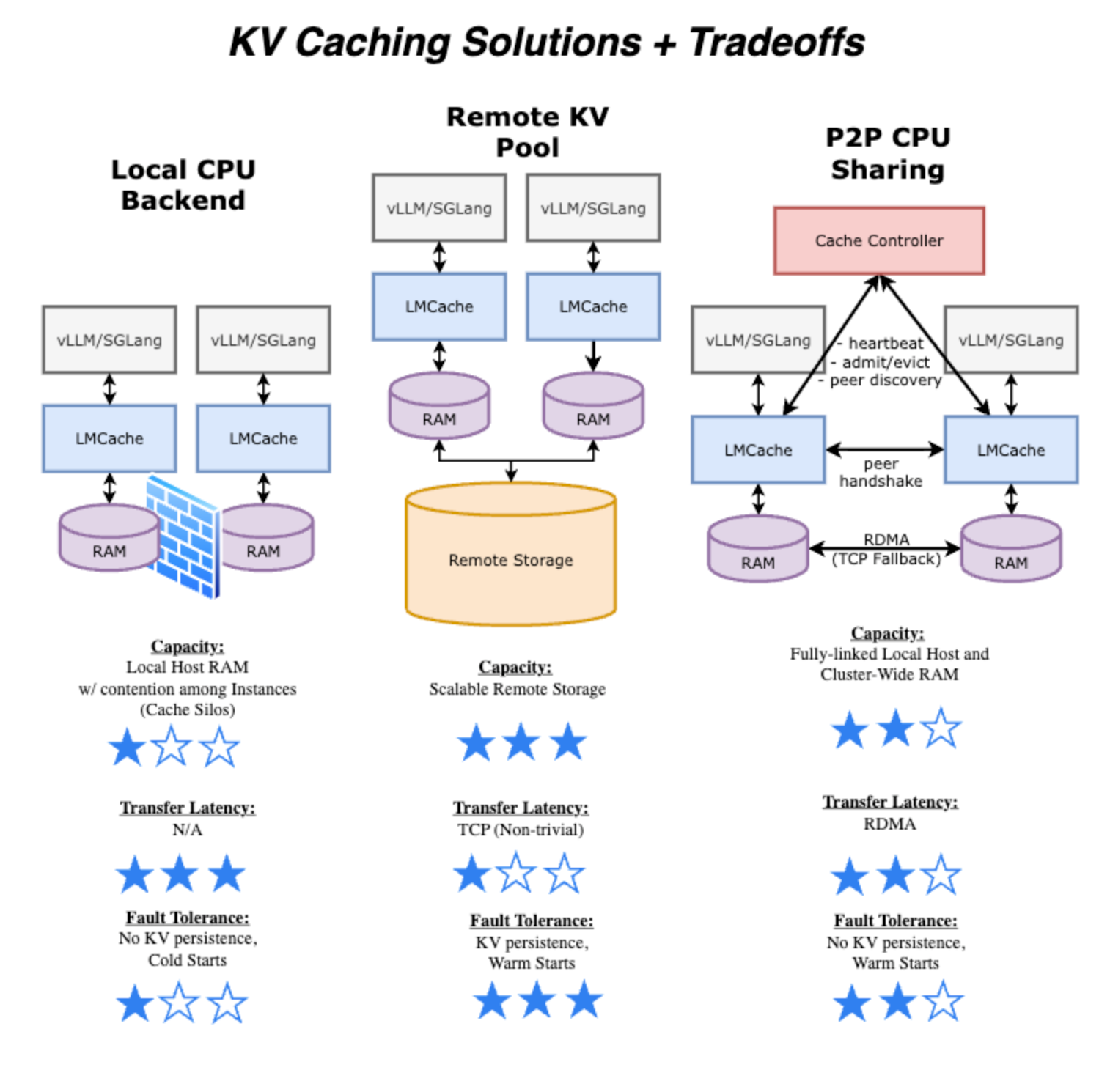
When evaluating KV caching strategies, teams typically consider three architectures, each with distinct tradeoffs:
Local CPU Backend: Fast transfer latency but limited to local host RAM, creating cache silos that prevent reuse across instances.
Remote KV Pool: Offers scalable remote storage and KV persistence for warm starts, but introduces TCP-bound transfer latency and requires managing additional stateful infrastructure.
P2P CPU Sharing: Combines the speed of local access with cluster-wide cache sharing through RDMA-enabled peer communication, though without persistent storage across cold starts.
How Tensormesh Addresses This Challenge
Through LMCache's new P2P architecture, which powers Tensormesh's intelligent routing, instances can now share KV cache across peers without the overhead of external cache services. The system uses a controller-based architecture to coordinate cache discovery while maintaining high-performance RDMA transfers between peers.
In benchmark testing with long-document QA workloads, the results were significant:
- 4x improvement in time-to-first-token (TTFT)
- 5x improvement in total query completion time
- All achieved by eliminating redundant prefill operations through intelligent cache sharing
For Tensormesh customers, this translates directly into lower inference costs and faster response times, especially for workloads with repeated context patterns like agentic workflows, document processing, and multi-turn conversations.
Built for Production, Not Just Benchmarks
What makes this collaboration particularly valuable is Tencent's focus on production-grade reliability. The partnership has produced:
- Fault-tolerant architecture with heartbeat-driven recovery
- Fine-grained locking for high-throughput concurrent operations
- Elastic scaling with millisecond worker registration/deregistration
- Controller dashboard for real-time cluster monitoring
The Open Source Advantage
Because LMCache is open source, improvements from collaborations like this one benefit the entire AI infrastructure community while making Tensormesh's caching layer more robust with each release.
For organizations managing KV cache infrastructure or looking to reduce GPU costs for inference workloads, the combination of LMCache's capabilities and Tensormesh's intelligent optimization layer represents one of the most cost-effective solutions available today.
Technical Deep Dive: For teams interested in the full technical details of the P2P architecture, controller design decisions, and benchmark methodology, check out the complete blog post here.
Act On Cost Issues: Want to see how Tensormesh can reduce your inference costs? Join the beta now for your specific workload optimization needs.











































