Enterprise AI Vendor Lock-In: What It Costs When Your Provider Pulls Access

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
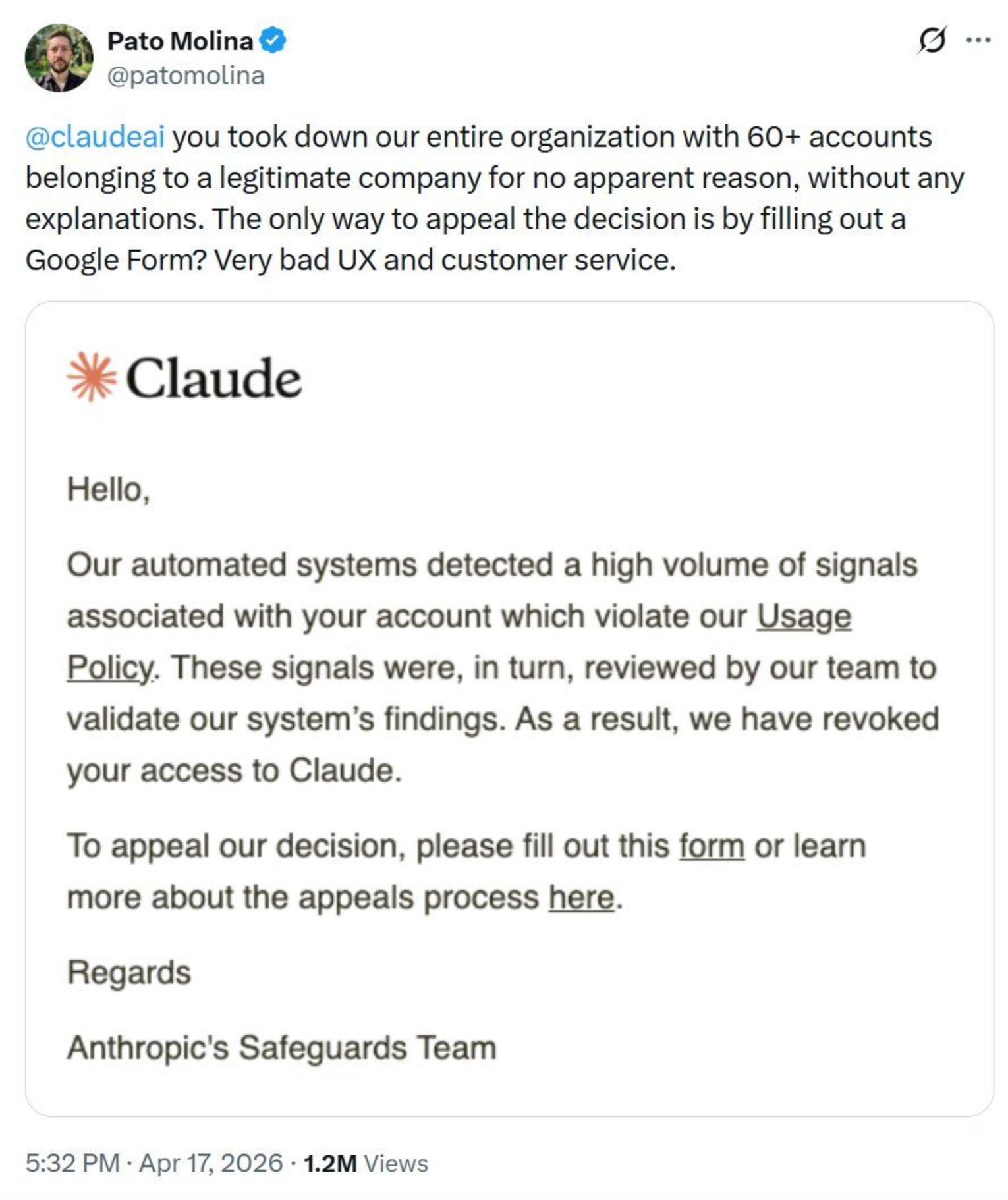
In April 2026, a verified user posted publicly on X after Anthropic's Safeguards Team revoked access for his entire organization, more than 60 accounts belonging to a self-described legitimate business, without identifying a single violated policy clause or specific output. The termination email cited automated systems detecting unspecified signals and offered a Google Form as the only option for appeal. The post circulated widely across engineering communities, and the responses it generated reflected something beyond sympathy, with leaders across infrastructure and platform teams noting that the scenario was one they had considered but never formally planned for.
A Pattern Across Every Major Closed-Weight Provider
Two other publicly documented cases reflect the same structural dynamic, each involving different providers and different stated rationales but arriving at the same outcome: access terminated at the provider's sole discretion, with no contractual liability for downstream business losses and no guaranteed restoration path available to the customer.
- OpenAI, June 2024: API access was blocked across dozens of unsupported countries with minimal notice, leaving startups unable to serve international customers and with insufficient time to migrate their products before the enforcement date.
- Anthropic, June 2025: Windsurf's direct access to Claude was cut with less than five days notice amid OpenAI acquisition rumours, affecting thousands of downstream developers despite no compliance failure on Windsurf's part. The reason given was competitive strategy, not anything the customer had done wrong.
- Anthropic, August 2025: OpenAI's API access was revoked entirely over a terms of service dispute, with no independent appeals process available and access ending on the provider's own timeline.
Your AI Provider's Terms Give Them Every Advantage
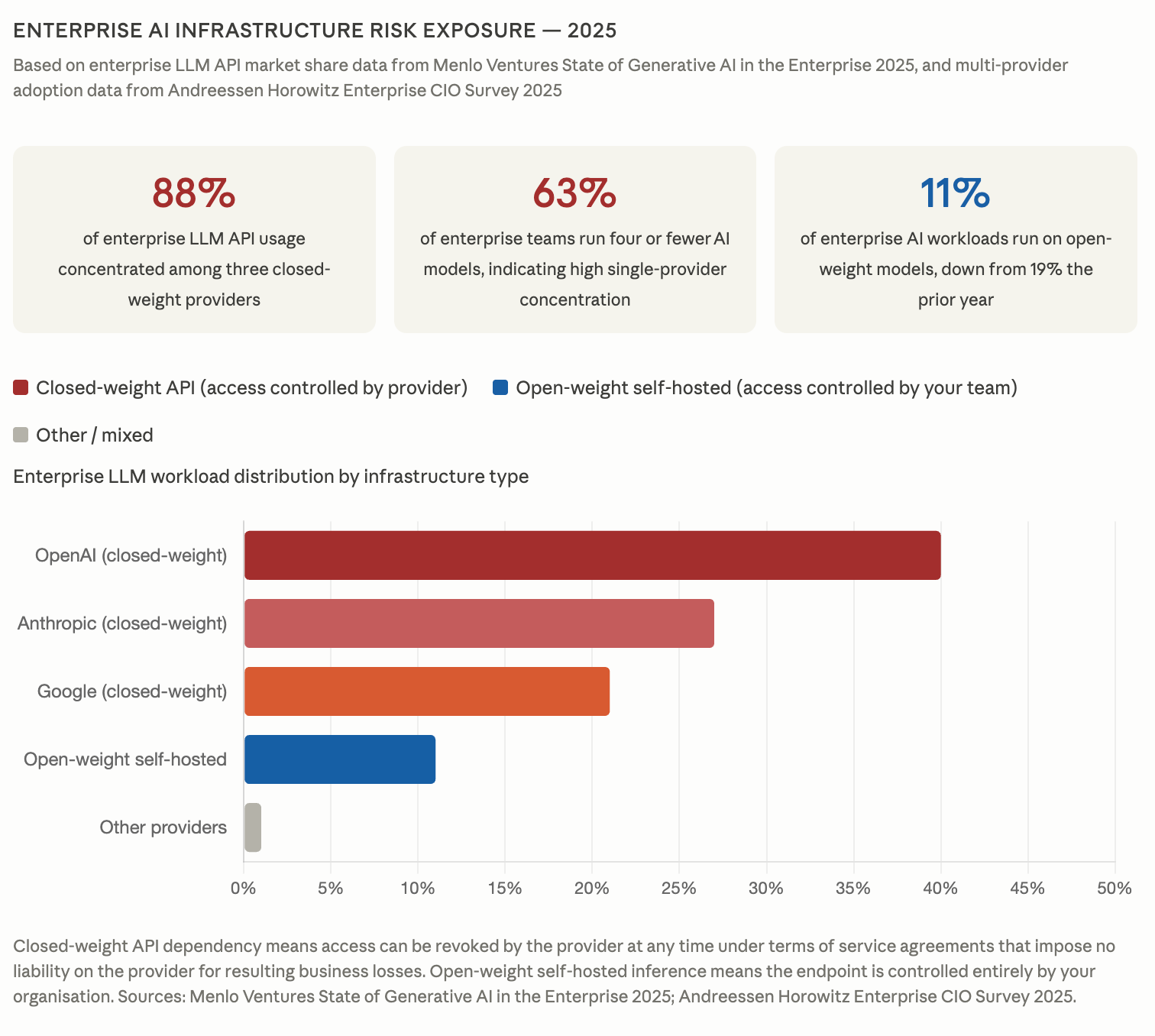
Every major closed-weight provider's publicly available terms of service share the same underlying architecture: the provider determines unilaterally what constitutes a violation, no specific content needs to be identified before enforcement action is taken, no appeals timeline is guaranteed, and no liability applies for the business losses that follow a termination decision. The cost picture is more nuanced and volume-dependent, and we cover it in detail separately, but for teams running at meaningful inference scale the economics of self-hosted open-weight models are increasingly competitive with per-token API pricing.
The contrast with traditional cloud infrastructure is worth making explicit for teams conducting risk assessments. When Amazon Web Services or Google Cloud experience an outage, contractual uptime obligations apply and the provider carries strong commercial incentives to restore service as quickly as possible, whereas when a closed-weight AI provider terminates access, none of those mechanisms exist, leaving your SLA obligations to your own clients fully intact while your infrastructure provider owes you nothing in return.
Andreessen Horowitz's 2025 survey of enterprise CIOs found that 37% now run five or more models in production, up from 29% the previous year, with multi-provider strategies increasingly driven by the desire to reduce exactly this kind of single-vendor concentration risk.
Why Open-Weight Models on Managed GPU Cloud Eliminate the Risk Entirely
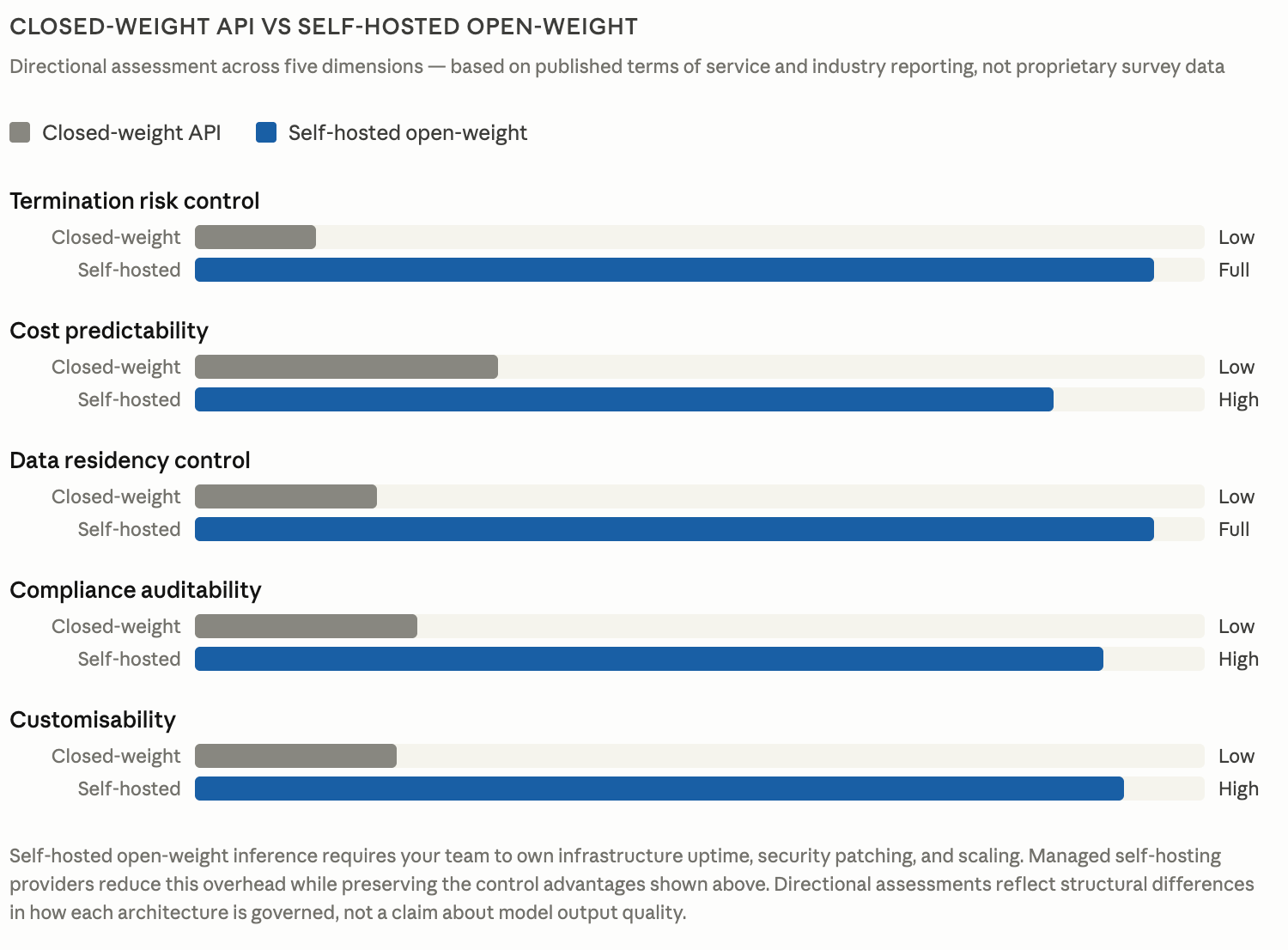
When your inference runs on infrastructure your team controls, the scenarios described above become architecturally impossible. Unlike closed-weight API providers, Tensormesh does not control the model weights your inference runs on, meaning no policy enforcement team can revoke your access to them regardless of whether you are running on dedicated or serverless GPU infrastructure. The provider relationship ends at the point of model weight selection rather than persisting through every inference call, which means no third-party enforcement system has access to your endpoint and no acceptable use policy can reclassify your use case overnight.
The data governance case is equally direct. For teams operating under HIPAA, GDPR, or financial services compliance requirements, running inference on open-weight models removes the boundary crossing entirely:
- Prompts never leave your infrastructure perimeter
- Provider data retention policies and subprocessor arrangements no longer sit outside your audit trail
- Compliance implementation and the audit process needed to demonstrate it become significantly more straightforward
The performance gap that once made closed-weight dependency feel necessary has narrowed considerably, with leading open-weight models now competitive across reasoning, code generation, and instruction-following for the majority of enterprise use cases. The cost picture is more nuanced and volume-dependent, and we cover it in detail separately, but for teams running at meaningful inference scale the economics are increasingly competitive with per-token API pricing.
The honest tradeoff is that your team takes ownership of uptime, security patching, and scaling without a vendor support line for production incidents. For any organisation where a termination event would cause serious damage across client relationships and SLA commitments, that tradeoff resolves clearly in favour of open-weight infrastructure.
What Tensormesh Provides
Tensormesh is GPU cloud infrastructure built for enterprise teams who want the control of self-hosted open-weight inference without the overhead of building and maintaining the underlying compute themselves. Standard single-model deployments typically move from initial scoping to a live endpoint within two weeks, with more complex configurations scoped individually during the infrastructure assessment.
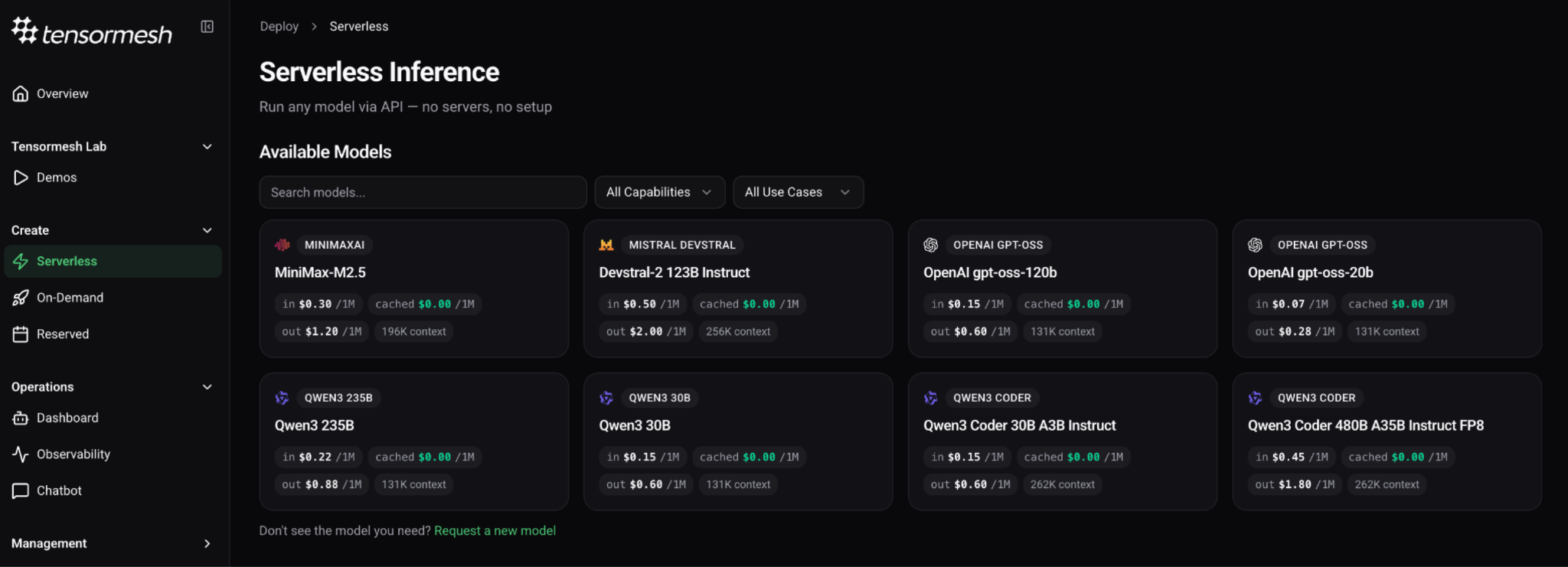
Reasoning and general purpose
- Qwen3 235B — Alibaba's flagship open-weight reasoning model, built for complex multilingual and instruction-following tasks across enterprise workflows
- Qwen3 30B — Efficient general-purpose deployment at single-GPU cost for teams prioritising inference efficiency at scale
- OpenAI gpt-oss-120b and gpt-oss-20b — OpenAI's open-weight releases, fully self-hostable with none of the access dependency risk of their commercial API endpoints while drawing on the same instruction-following training lineage
Coding and agentic workloads
- MiniMax-M2.5 — MIT-licensed open-weight model trained extensively across real-world coding and agentic environments, well suited to teams running complex multi-step development workflows at scale
- Devstral-2 123B Instruct — Purpose-built for agentic software engineering with a 256k context window designed for whole-repository workflows. Enterprise legal teams should note that its modified MIT license carries restrictions for organisations with monthly revenue above twenty million dollars and should verify commercial terms directly with Mistral before deployment
- Qwen3 Coder 30B A3B Instruct — Production coding tasks at single-GPU cost with strong instruction-following performance
- Qwen3 Coder 480B A35B Instruct FP8 — Frontier-level code generation for teams where output quality is the primary constraint rather than inference cost
For teams with requirements outside the curated catalog, Tensormesh connects directly to Hugging Face, giving access to over 300,000 open-weight models that can be deployed on your infrastructure without vendor approval, usage review, or third-party negotiation of any kind.
What Comes Next
Closed-weight APIs were the right starting architecture for most enterprise AI teams and remain a reasonable fit for certain use cases, but for teams where AI inference has become genuinely load-bearing infrastructure, the question worth asking is whether a commercial agreement that offers no termination protection, no appeals mechanism, and no provider liability still makes sense as a long-term foundation to build on.
The infrastructure and model quality are in place, and the migration path is more straightforward than most teams expect when they begin the assessment.
Explore Tensormesh’s model catalog
Don't see the model you need? Let us know
Try Tensormesh now with $100 in free GPU Credits
Sources
- @patomolina, X, April 2026. https://x.com/patomolina
- "OpenAI to pull plug on 'unsupported' nations from July 9," The Register, June 25, 2024. https://www.theregister.com/2024/06/25/openai_unsupported_countries/
- "Windsurf says Anthropic is limiting its direct access to Claude AI models," TechCrunch, June 3, 2025, and "Anthropic co-founder on cutting access to Windsurf," TechCrunch, June 5, 2025. https://techcrunch.com/2025/06/03/windsurf-says-anthropic-is-limiting-its-direct-access-to-claude-ai-models/
- "Anthropic cuts off OpenAI's access to its Claude models," TechCrunch, August 2, 2025. https://techcrunch.com/2025/08/02/anthropic-cuts-off-openais-access-to-its-claude-models/
- "How 100 Enterprise CIOs Are Building and Buying Gen AI in 2025," Andreessen Horowitz, June 2025. https://a16z.com/ai-enterprise-2025/
- "2025: The State of Generative AI in the Enterprise," Menlo Ventures, December 2025. Source of enterprise LLM market share data showing 88% concentration among three closed-weight providers. https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/














































