Tensormesh Inference: Cheaper LLM Inference for AI Agents


Tensormesh Inference: Cheaper LLM Inference for AI Agents
Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
The problem: Your agent pays to re-read every turn
Every agent builder knows the pattern: a long system prompt, a catalog of tools, a few-shot example block, a steadily growing conversation history, and a ReAct loop that adds another tool call observation on every step.
Each time your agent calls the model, it resends most of that context, and the model quietly redoes most of the same work.
That's the tax most agent developers don't see on their bill. You're paying the model to re-process the same system prompt, tool definitions, and conversation history on every single turn. For an agent performing dozens of LLM calls inside a single task, that adds up to significant compute spent re-deriving context the model already understood.
What's actually happening: Meet the KV cache
When a transformer model processes your prompt, it doesn't just read tokens. At every layer, it computes Key and Value vectors for each token. Those vectors are how later tokens "attend back" to earlier ones, effectively encoding the model's understanding of your prompt. Together, those vectors are called the KV cache.
Computing the KV cache is the "prefill" phase of inference, and for long prompts, prefill dominates both your latency and your cost. Once it's computed, generating each new output token is comparatively cheap.
Most of your agent's bill is the prefill phase, and most of the prefill phase is recomputing context the model has already seen before. If the model could keep the KV cache around between calls, or share it across requests, your agent would get faster and cheaper without you changing a line of code.
Why Agents Pay the Highest Inference Tax
Agent workloads have a shape that's almost designed to expose this problem:
- Heavy stable prefix. The system prompt and tool catalog at the front of every call are identical for the entire lifetime of the agent. For many agents, that's the majority of every prompt.
- High call volume per task. A single user request can trigger dozens of LLM calls and each one re-pays for the prefix.
- Long, growing trajectories. ReAct, planner/executor, and multi-agent patterns accumulate context, which means every step re-reads everything that came before it.
- Cross-session reuse. A customer support agent runs thousands of conversations a day, all of which start with the same setup.
If you're using a closed-source API, the platform may do some prefix caching for you on its own schedule with limited visibility and no real controls. You don't get to decide what's cached, when it's evicted, or whether the cache survives across sessions. On occasion you will get a faster response and hope for the best. That's the gap Tensormesh was created to fill.
What Tensormesh Inference is
Tensormesh Inference is an optimization and management platform for self-hosted LLM inference. It sits on top of the vLLM inference engine, the Tensormesh LMCache stack, and any cloud provider, and it exposes the KV cache as something you can program against.
You can bring the model and cloud while we give you the controls to make KV caching work for your agent.
There are two sets of capabilities:
- Optimization: KV cache CPU offloading and KV cache external storage offloading.
- Management: Observability, elasticity, security, and usage.
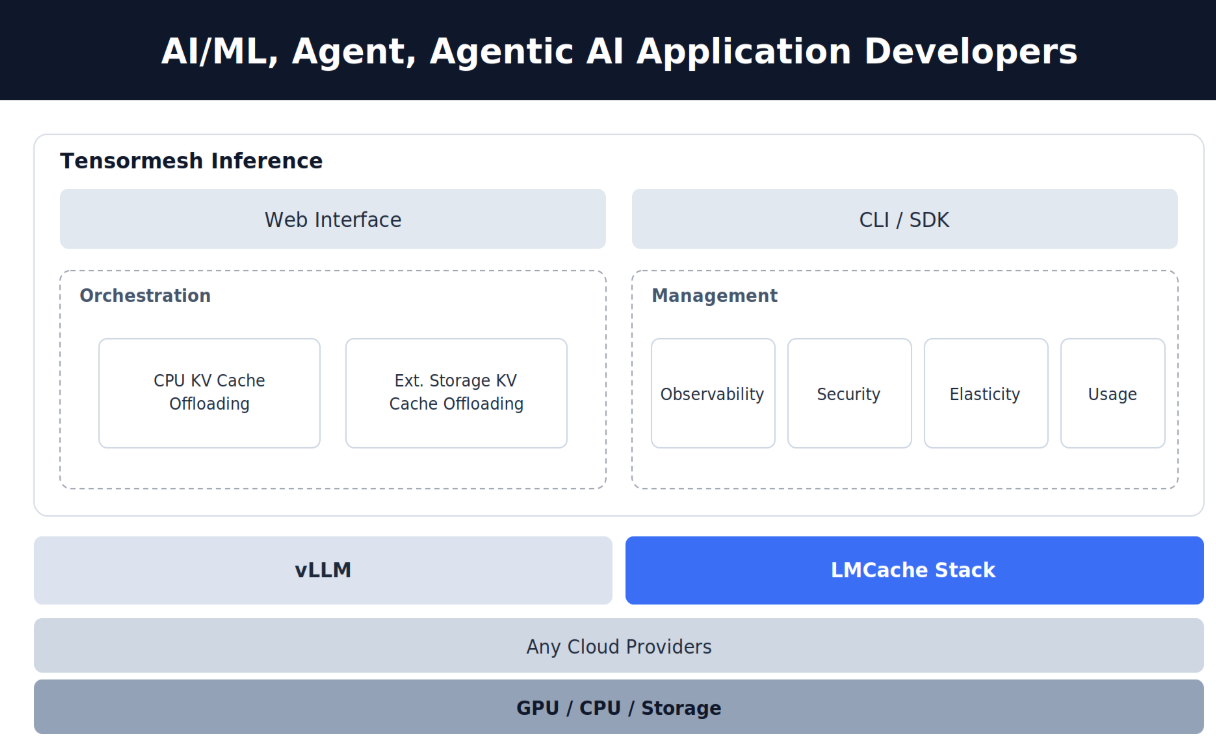
Optimization: Control where the KV cache lives
These are the levers an agent developer actually wants when they care about latency and cost.
KV cache CPU offloading
GPU memory (HBM) is small and expensive. Host CPU memory is much larger and much cheaper. Tensormesh lets you push prefixes that aren't actively in use out of GPU memory and into CPU memory, so the GPU stays free for more concurrent requests or longer contexts while your prefix stays close enough to bring back in milliseconds.
When your system prompt or tool catalog isn't being actively used, it doesn't have to fight for GPU room with everything else. It sits in cheaper memory until you need it.
KV cache external storage offloading
For prefixes that should outlive a single session, like your agent's persona, your tool definitions, and the boilerplate at the start of every conversation, you can persist the KV cache to external object or block storage. When a new session starts, the cache is hydrated back in fast instead of being recomputed from scratch.
Restarts, autoscaling events, and fleet reshuffles stop costing you cold starts. Your agent's "always-there" context becomes something you actually keep, instead of something you accidentally throw away every few minutes.
Management: Run inference like production infrastructure
Optimization gets you the savings while management gets you the confidence to run it in production.
Observability – See exactly which prefixes are cached, where they live (GPU, CPU, external storage), and how often they're hit. The cache stops being a black box and becomes something you can reason about and tune.
Elasticity – Scale your inference fleet up and down without losing your warm caches. Autoscaling events no longer reset your agent's effective memory.
Security – Self-hosted by design. Your prompts, your tool definitions, and your conversation history stay in your environment, not on a third-party API.
Usage – Track cache hit rates, token savings, and cost per agent or per workload. Know exactly where your inference dollars are going and where they're being saved.
What makes Tensormesh Inference different
$0 on cached input tokens
Most inference providers charge you for cached tokens, either at a discount or at full price, leaving you with a bill that's hard to predict. We don't charge for cached input tokens at all, and our standard inference rates come in below industry norms. The more your workload reuses context, the larger your savings get, which is exactly why agents benefit most.
vLLM-native and cloud-agnostic by design
Bring the inference engine you already trust and the cloud you already run on. Tensormesh adapts to your stack, not the other way around. We see this as the bare minimum for any platform that wants to sit in your inference path.
KV caching as a product surface, not a hidden cost
Most inference platforms hide the cache behind a billing line. We expose it as something you can place, observe, and act on programmatically. For agent and long-context workloads, this is where the real cost savings live, and it's only accessible if the platform was designed to expose it.
Who Tensormesh Inference is for
- Agent and agentic AI developers whose workloads are dominated by stable prefixes, system prompts, tool catalogs, and growing trajectories, and who can't get real cache controls out of closed-source APIs.
- AI/ML platform teams running LLM inference in production and watching the GPU bill scale faster than revenue.
- Teams running open-weight self-hosted models who want the economics without building their own cache tiering, eviction policy, and observability stack from scratch.
How to get started
Tensormesh provides Python SDK and CLI support, with integration into your inference runtime, agent code, and CI pipelines
1. Try Tensormesh → Visit Tensormesh Inference for $100 credit
2. Integrate & Deploy → Plug into your existing framework in minutes.
3. Scale Smarter → Watch latency drop and savings stack up.








































