How We Optimized Redis for LLM KV Cache: 0.3 GB/s to 10 GB/s


Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
KV caches accelerate LLM inference, but their aggregate size quickly exceeds GPU memory, requiring a scalable, cluster-level storage backend. Redis is a natural fit, but its standard Python SDK delivers only 0.3 GB/s of retrieval throughput, far below what's needed to outpace GPU recomputation. In partnership with Redis, we rebuilt the client down to C++, achieving a 30x throughput improvement (0.3 → 10 GB/s) and a 40% reduction in end-to-end round time on production workloads.
Who We Are
We were founded by the creators of LMCache, the open-source KV caching engine we built and continue to maintain, integrated widely across the inference ecosystems (including all 3 major serving engines: vLLM, SGLang, TensorRT-LLM) and various orchestration stacks (NVIDIA Dynamo, llm-d, vLLM Production Stack, etc.)
This post walks through a specific piece of that work, making Redis a high-performance external storage backend for LMCache. We took Redis client throughput from 0.3 GB/s to 10 GB/s, and here's what that means for real-world inference.
Why KV Cache Offloading Matters for LLM Inference
Large language model inference is expensive. When a user sends a prompt that shares a prefix with a previous request, the GPU recomputes attention over tokens it's already seen. KV cache offloading solves this through storing the computed key-value tensors externally and retrieving them instead of recomputing.
LMCache manages a three-tier memory hierarchy for this purpose: L0 (VRAM), L1 (Host RAM), and L2 (external storage). Redis is a natural fit for external storage as it runs everywhere (AWS, GCP, Azure, on-prem), teams already know how to operate it, and it's battle-tested at scale. In July 2025, we integrated Redis into LMCache's southbound storage tree. Then we set about making it as fast as possible.
Why KV Cache Is Not a Typical Redis Workload
Redis typically handles small metadata payloads in the 1–10 KB range. KV cache chunks range from 500 KB to 40 MB. A single 10,000-token request on Llama 3.1 8B generates roughly 1.2 GB of KV cache data.
The optimization target is different too, as traditional Redis use cases optimize for latency and ops/s. For KV cache offloading, what matters is throughput in GB/s and tail latency — every chunk must arrive before inference can continue. We set a 2 GB/s retrieval SLO, the threshold where loading from Redis outpaces GPU prefill on modern datacenter hardware.
Why 2 GB/s? Attention during prefill is compute-bound at O(n²) in sequence length, while retrieval is bandwidth-bound at O(n). As context length grows, prefill cost grows faster than retrieval cost, widening the window where caching wins. The exact crossover depends on GPU generation and model size — a topic we plan to cover in a future post.
Starting with the standard redis-py SDK, we measured 0.278 GB/s. That's roughly 7x below our target.
Validating Feasibility with memtier_benchmark
Before writing optimization code, we validated that the 2 GB/s target was achievable. Using memtier_benchmark (Redis's C-based benchmarking tool) with 4 MB payloads against a local Redis 8.2 instance:

5.85 GB/s on GET. The SLO was reachable, however, the client was the bottleneck. Our optimization work fell into three phases.
Phase 1: Pure-Python Redis Client — 0.3 to 5 GB/s
Zero-copy protocol handling (0.3 → 2 GB/s)
We wrote a custom RESP protocol parser that enforces zero-copy on both send and receive paths. On sends, we use scatter-gather writes via sendmsg. On reads, recv_exactly_into writes directly into the caller's buffer but no intermediate copies or allocations.

This alone delivered a 7x improvement in retrieval throughput.
Exploiting fixed-size KV cache chunks (2 → 4–5 GB/s)
LMCache chunks KV cache along the token dimension. Normally each chunk carries separate metadata recording its actual length, requiring two Redis operations per chunk. We made two changes:
- Drop the last partial chunk, making all chunks a uniform fixed size. This eliminates metadata entirely, halving the number of Redis round trips. The dropped tokens are recomputed during the next prefill pass, which is negligible relative to the retrieval savings on the remaining chunks.
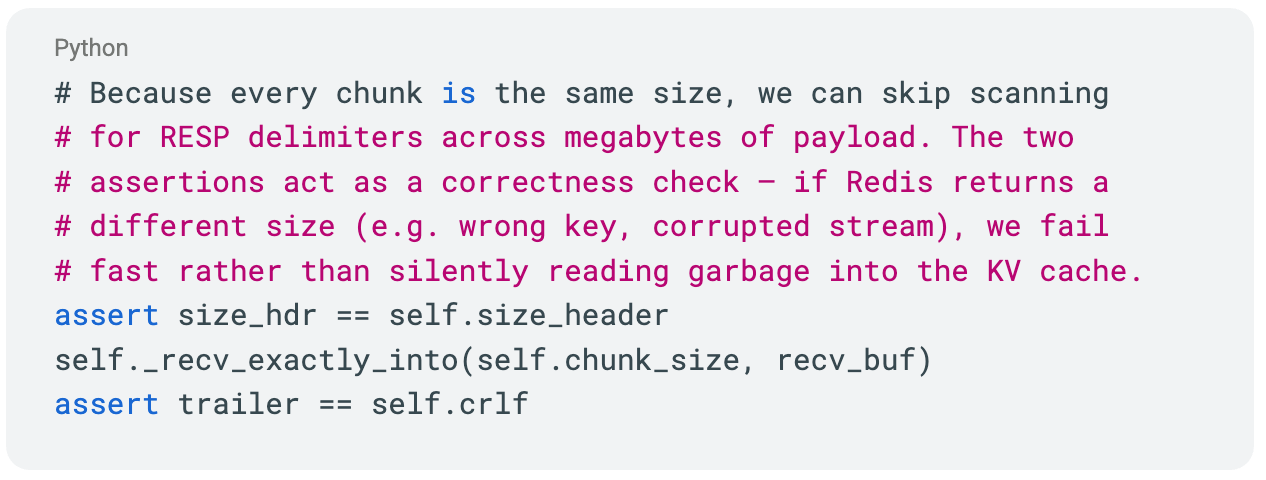
- Fixed-size parsing: since the parser knows the payload size in advance, it skips RESP delimiter scanning across megabytes of data. Read the size header, assert it matches, read exactly that many bytes into the receive buffer.
At this point our pure-Python client matched memtier_benchmark's C-based throughput and we hadn't left GIL territory yet.
Phase 2: Building the Python-C++ Boundary — 5 to 10 GB/s
vLLM and LMCache are Python applications, so the top-level interface must remain Python. The challenge was building a C++ client core while designing a synchronization boundary that minimizes Python-side scheduling overhead.
Why the GIL matters for I/O-bound LLM workloads
Profiling revealed that even with 8+ threads doing socket I/O, the GIL caused implicit serialization. Two I/O completions arriving simultaneously would contend, and no new jobs could dispatch while one was scheduling. Our pybind11 layer releases the GIL on the first line of every call:

Batched, tiled KV cache operations
KV cache retrieval is all-or-nothing as all chunks for a request must arrive before inference continues. The client exposes only batched operations (BATCH_TILE_GET, BATCH_TILE_SET, BATCH_TILE_EXISTS). Within a batch, work is tiled across threads with each thread receiving a contiguous slice of the key range:

Non-polling completion via Linux eventfd
Getting results back to Python without polling or blocking was the trickiest design problem. When the last tile completes, the C++ worker writes to a Linux eventfd. Python's event loop has a reader registered on that fd, so the kernel wakes Python avoiding waiting. Multiple tile completions coalesce into a single event; Python sees one wakeup per batch regardless of thread count.

Standalone result: 9–10 GB/s on a 128-vCPU bare-metal node with ConnectX-7 NICs — resulting in a 30x improvement over the original redis-py client. With full LMCache integration, end-to-end throughput reached 7 GB/s (the remaining gap is partly GPU ↔ DRAM transfer). On faster GPUs (H100, B200), the NIC demand increases to keep retrieval ahead of prefill — but longer context lengths also increase the compute saved, so the tradeoff remains favorable.
All optimizations are available in LMCache PR #2541.
Phase 3: Cloud Tuning for Production Redis Deployments
Local throughput is meaningless if it collapses over the network. Moving to GCP introduced new bottlenecks:
- Same AZ + VPC is non-negotiable — cross-AZ drops bandwidth 5–10x.
- TCP stream count: bandwidth converges around 64 parallel streams at ~40 Gbps on GCP VMs. Matching client worker count to this achieves >90% of raw iperf3 throughput.
- TCP buffer sizes: GCP defaults (~212 KB) are too small for multi-MB KV cache transfers.
After tuning, self-hosted Redis on GCP (same AZ/VPC) reaches 6 GB/s standalone. Redis Cloud currently reaches ~2.6 GB/s, partly because managed offerings don't yet expose the highest-tier networking options on GCP and AWS. We expect this gap to narrow as we co-tune with the Redis team across both platforms.
End-to-End LLM Inference Benchmark Results
This led us to the question, does retrieving KV cache from Redis over the network beat recomputing on the GPU?
We ran a long-document QA workload (benchmark source) across two GCP VMs in the same VPC — an 8× A100 GPU node and a c2d-standard-112 Redis node — with 40 documents at 40,000 input tokens each, 100 output tokens, and a 66.7% cache hit rate:
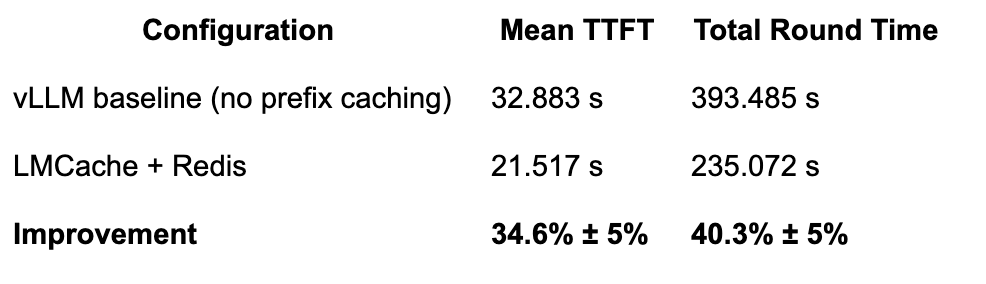
Cache hit rate? This models a 3-round conversation. In multi-turn settings with N homogeneous rounds, KV cache reuse is (N−1)/N — so 67% is actually conservative for users chatting beyond 4 rounds. Real-world hit rates depend on prefix overlap patterns, but conversational and agentic workloads tend to be favorable for KV cache reuse.
Wondering whether KV cache offloading pays for itself on your workload? Try the Tensormesh Storage ROI Calculator.
Lessons Learned Optimizing Redis for LLM Inference
Isolate phases. The standalone client, the Python-C++ integration, and cloud networking are three separate problems with different bottlenecks; solve them separately.
Define the right metric. Tail latency, not average latency. Throughput in GB/s, not ops/s.
Exploit workload invariants. KV cache chunks have a known, fixed size per batch. This one property unlocked aggressive parsing, eliminated metadata, and simplified the protocol.
The GIL matters for I/O. Profiling reveals it, don't assume otherwise.
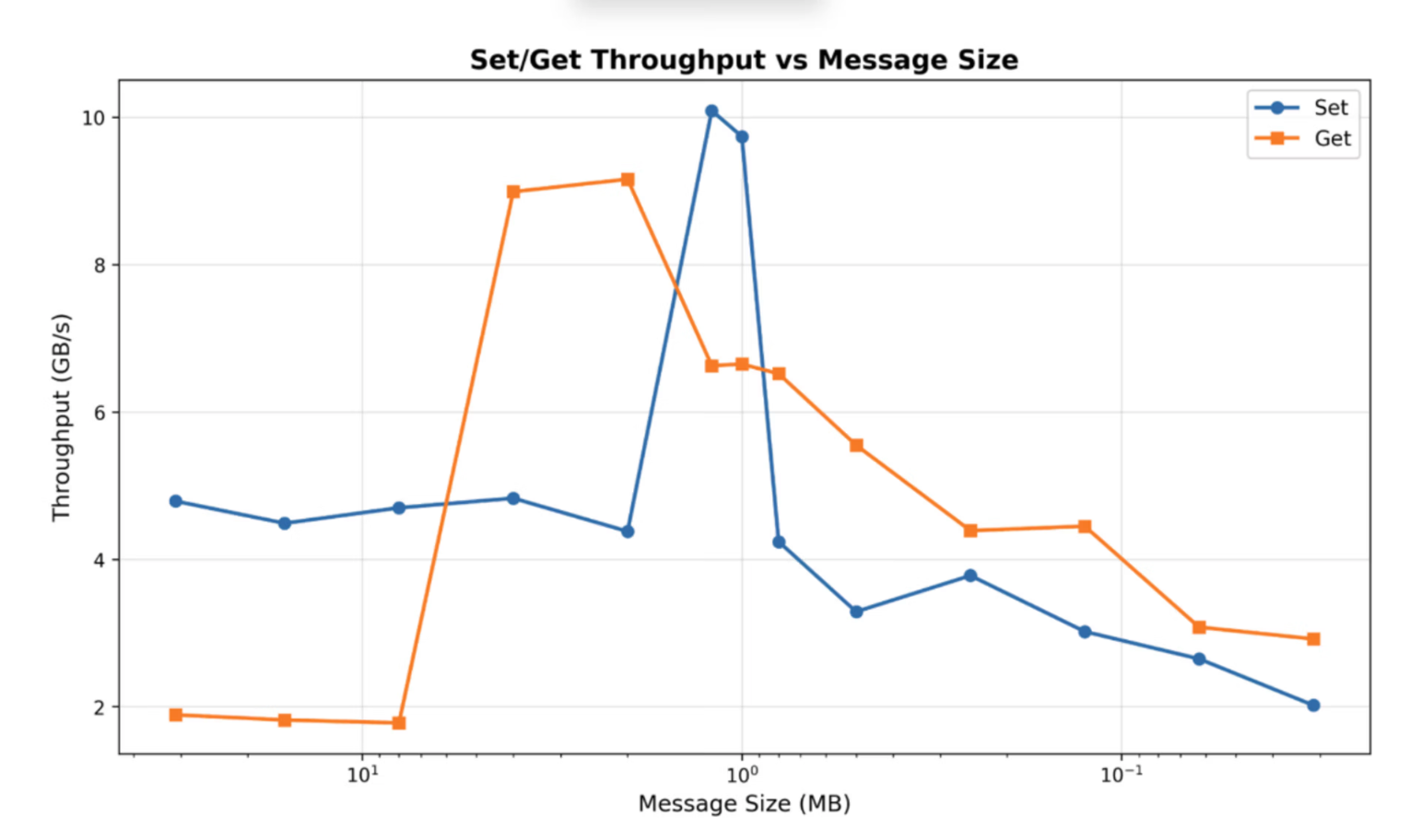
Don't assume monotonicity. Throughput vs. chunk size is non-monotonic and machine-specific, it’s important to always sweep on target hardware.
General systems toolkit: batching, zero-copy, non-blocking, non-polling, tiling. We're generalizing these optimizations into a native southbound protocol in LMCache: PR #2642.
What's Next for Tensormesh and LMCache
We’ve published results on multi-node P2P KV cache sharing with Tencent, and are continuing to expand cross-node caching capabilities.
On the infrastructure side, we're expanding cloud tuning to AWS, further optimizing Redis Cloud performance with the Redis team, and generalizing the high-performance client patterns across LMCache's storage backends.
Want to try LMCache with Redis? Check out the LMCache GitHub repo or reach out to the Tensormesh team.











































