KV Cache isn't just Cache, it's Memory: A Guide for LLM & Agent Devs


KV Cache isn't just Cache, it's Memory: A Guide for LLM & Agent Devs
Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
If you've built anything serious on top of an LLM in the last year, whether that's a chatbot holding long conversations, a RAG pipeline pulling in thousands of tokens of context, or an agent that grinds through tool calls until it bumps into the million-token ceiling, you've already collided with the KV cache. You may not have called it by that name, though you've almost certainly called it something less polite, like "latency," "context limits," or "the GPU bill."
Treating KV cache as plumbing, an implementation detail of the transformer that the inference engine quietly handles for you is going to become more and more costly.
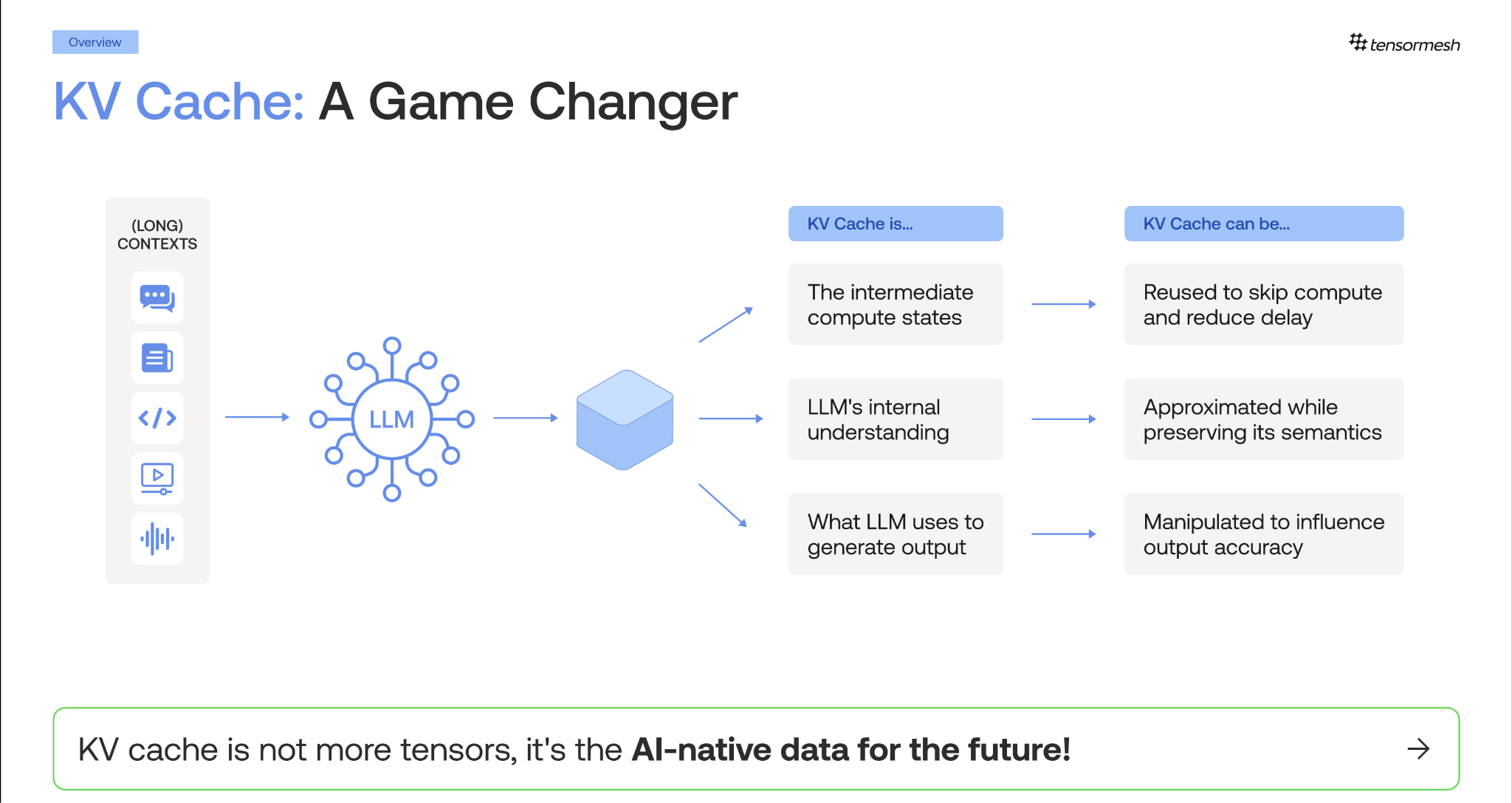
KV cache is a first-class design surface
Model-wise, DeepSeek V3 and V4 were optimized heavily around KV cache size, with explicit tradeoffs about which parts of attention get aggressively compressed and which stay dense. Agent-wise, Claude Code's context compaction is built to preserve prefix reuse, and reports for which reasons your prefix gets broken (system prompt changes, tool changes, conversation changes, model changes).
KV cache is actively shaping how the best models and agents get architected from the beginning, and the teams who win on cost and latency a year from now will be the ones who treated KV cache compatibility and compression as design inputs rather than afterthoughts.
What production workloads actually look like
The cache-friendly fraction of real-world traffic keeps climbing, and the patterns are getting more diverse:
- Chatbots have prefix reuse on every single turn, since the entire conversation history is shared across every subsequent generation.
- RAG is one of the strongest non-prefix reuse cases anywhere in the wild, where the same documents get pulled into different prompts, in different orders, for different users, and the KV cache for that document content is enormous yet almost always recomputed from scratch.
- Agent workloads like Claude Code routinely fill the million-token context window, with every tool call replaying an ever-growing prefix.
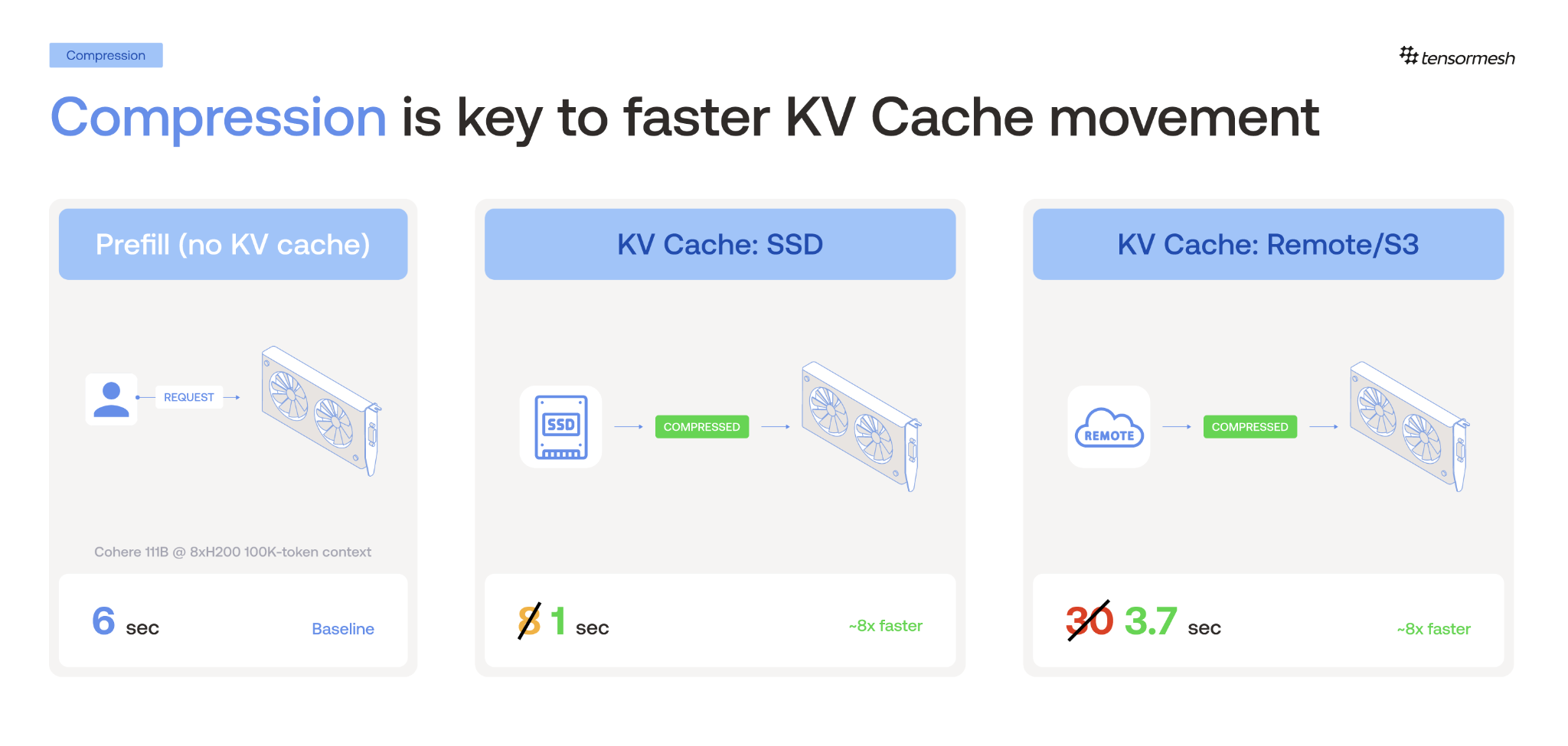
Meanwhile, the GPU is pinned while the rest of the machine sits largely idle. DRAM has bandwidth to spare, NVMe has capacity to spare, and there are perfectly good database tiers waiting for work that never arrives. The inference stack has its most expensive resources overworked (FLOPs and HBM bandwidth) while the cheaper ones are untapped, which leaves an obvious opportunity for CPU and SSD layers to carry load that GPUs are currently burning on redundant recomputation.
Semantic nitpicking: what is "cache"?
When systems people say "cache," they mean redundant data placed closer to where it will be used (e.g. memoization in dynamic programming, L1/L2 CPU caches, or CDNs), which is a space-for-time tradeoff. That description doesn't actually fit the KV cache, which is better understood as the model's working memory for a particular sequence. The more accurate word is state.
State can be:
- Computed offline, by pre-warming the cache for documents you already know you'll serve.
- Reused across non-prefix boundaries, so that the same chunk remains useful even when it appears in a different position within a different prompt.
- Reused across models, where with the right machinery the state derived in one model can seed another.
- Compressed, not in the gzipped sense but semantically compressed in the way that MLA does it.
- Analyzed to glean more human understandable insights into what the model is "thinking" during its generation
- Edited, with quality interventions applied to the state itself before generation continues.
None of those operations belong to an L2 cache; they belong to a database. The KV cache deserves to be a first-class data citizen in your stack, with the lifecycle, observability, and tooling that implies, rather than a systems-level afterthought hidden behind your inference engine.
The ecosystem is catching up, slowly and what's next
The first wave of LLM infrastructure caching landed at the wrong layer of the stack, and the consequences of that choice are still working their way through the ecosystem. The early focus was on text and strings, with LangChain-style context management defining what people thought caching even meant. That layer was useful in its time, though it was always operating on raw prompts rather than on what the model actually computes. The next wave centered on embeddings, with RAG indices and vector stores becoming standard infrastructure. That work was important too, though it only addressed the retrieval half of the problem.
KV cache management is the layer that's finally moving from emerging to mainstream right now, and that shift is really just the beginning of a much bigger arc. Everything a language model computes during inference is potentially reusable state, including hidden states, activations, and encoder outputs for multimodal inputs. For video, audio, or images, the encoding step is often more computationally expensive than the prefill that follows, which makes those intermediate computations especially valuable to hold onto.
This is what we're building toward with LMCache: cache everything a language model produces, treat that state as data, and let it move freely across the memory hierarchy. The artifact you're computing is more valuable than the computation that produced it, and the current default of throwing it away after a single use is leaving enormous value on the table.

An aside about the code we're shipping
A new asymmetry is that producing code with AI assistance is faster than it has ever been, while reviewing code carefully still takes the same patience and attention that it always did. Intuitive and modular abstractions are the first thing to get sacrificed.
If we're going to build the next layer of infrastructure for LLMs, and treating KV cache as first-class state is a meaningful part of that, the abstractions we ship have to be ones that other people can read, extend, and challenge. The leverage from getting the layering right is enormous, while the cost of refactoring a year of accreted shortcuts is just as enormous in the other direction. That tradeoff is worth a little more discipline today.
If you're building agents or RAG pipelines and your GPU spend has been climbing faster than your traffic, the KV cache is the place to look, not as one more optimization to consider but as a fundamental design surface for the systems you're building.
Get started with Tensormesh
Try Tensormesh Inference in 3 simple steps with $100 credit
Step 1: Choose a model
Find the right serverless model for your workload using model, capability, and use case filters.
Step 2: Copy the API call
Use ready-made examples with your API key to connect through a familiar API pattern.
Step 3: Start sending requests
Run inference immediately with no servers to manage and no deployment step required











































