Solving AI Inference Latency: How Slow Response Times Cost You Millions in Revenue

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
The Millisecond Economy
Amazon discovered that every 100 milliseconds of latency costs them 1% in sales. Google found that an extra 0.5 seconds in search page generation time dropped traffic by 20%. For financial trading platforms, being 5 milliseconds behind the competition can cost $4 million in revenue per millisecond.
As AI becomes embedded in every customer interaction from chatbots to recommendation engines to real-time analytics, the latency crisis has become universal.
The AI Latency Challenge
AI inference introduces unique latency challenges that fundamentally differ from traditional web applications:
The Inference Pipeline
- Time to First Token (TTFT): The delay before the first word appears, critical for perceived responsiveness
- Time Per Output Token (TPOT): The speed of subsequent content generation
- Network Latency: Physical data travel time between user, server, and model
- Compute Latency: Processing time for the model to generate predictions
Each component compounds. For applications requiring real-time responses, customer support, voice assistants and fraud detection, these delays are dangerous for businesses.
The Complexity Problem
Large language models require massive computational resources. Each inference request involves loading model weights into memory, processing input tokens through multiple layers, generating output sequentially, and managing context windows. When AI applications chain multiple model calls, a pattern common in agent-based systems, latency multiplies. A single complex query might require 5-10 individual model invocations, each adding hundreds of milliseconds.
The Business Consequences: Why Latency Is Non-Negotiable
High latency transforms AI from competitive advantage to operational liability. The data proves to be unforgiving:
Immediate Revenue Impact:
- Users consciously notice slowness at 100 milliseconds
- 53% of users abandon applications taking 3+ seconds to load
- A single second of delay = 7% reduction in conversion rates
- For a business generating $100,000 daily, one second of latency costs $2.5 million annually
- Decreasing load time by 0.1 seconds boosts conversion rates by 10% and increases spending by 8%
- Walmart: Every 1-second improvement = 2% increase in conversion rate
Long-Term Competitive Damage:
Users who experience delays continue to engage less even after performance improves, this "latency hangover" erodes lifetime value long after the initial incident. In AI-driven markets, companies delivering superior response times command premium prices and customer loyalty, while slow platforms lose users to faster alternatives.
Fast inference also unlocks high-value use cases like real-time fraud detection, interactive AI assistants, and instantaneous recommendations, all requiring sub-100ms latency. Organizations constrained by latency simply can't compete in these segments.
Why Traditional Solutions Fall Short
Most organizations approach AI latency with conventional optimization tactics that miss the fundamental issue:
- More Powerful Hardware: The latest GPUs improve individual inference times but don't address systemic inefficiency. Organizations still pay full compute costs for each request.
- Model Quantization: Reducing model precision speeds inference by 2-3x but often sacrifices accuracy.
- Edge Deployment: Moving inference closer to users helps network latency but introduces complexity around distributed model management without addressing compute latency.
- Batch Processing: Grouping requests improves throughput but increases individual user latency.
These approaches treat latency as a hardware problem while ignoring the core inefficiency. Despite the repetitive nature of AI workloads, traditional architectures repeatedly recalculate identical computations because cache contention on the GPU prevents effective reuse.
Web applications solved similar problems decades ago through caching. AI inference has largely operated without equivalent mechanisms, each request triggers a complete recalculation, even for queries processed seconds earlier.
The Solution: Intelligent Model Memory Caching
Model memory caching recognizes that AI workloads contain massive redundancy. Customer service bots answer similar questions repeatedly. Recommendation engines process overlapping user profiles. Search systems handle common queries thousands of times daily.
How It Works:
- Identify Overlapping Computations: Detect when requests share prefixes, patterns, or contexts with previous queries
- Cache Intermediate Activations: Store the model's "memory" while intermediate computations generated during inference
- Reuse Cached Work: Retrieve cached activations for overlapping portions rather than recalculating
- Complete Novel Portions: Only perform new computations for unique aspects of each request
The Impact:
Cached components serve in sub-millisecond timeframes while novel computations proceed at normal speed. The result: 5-10× cost reduction and dramatically faster time-to-first-token without sacrificing quality. As workload patterns emerge, cache efficiency compounds, creating sustainable performance advantages that traditional optimization can't match.
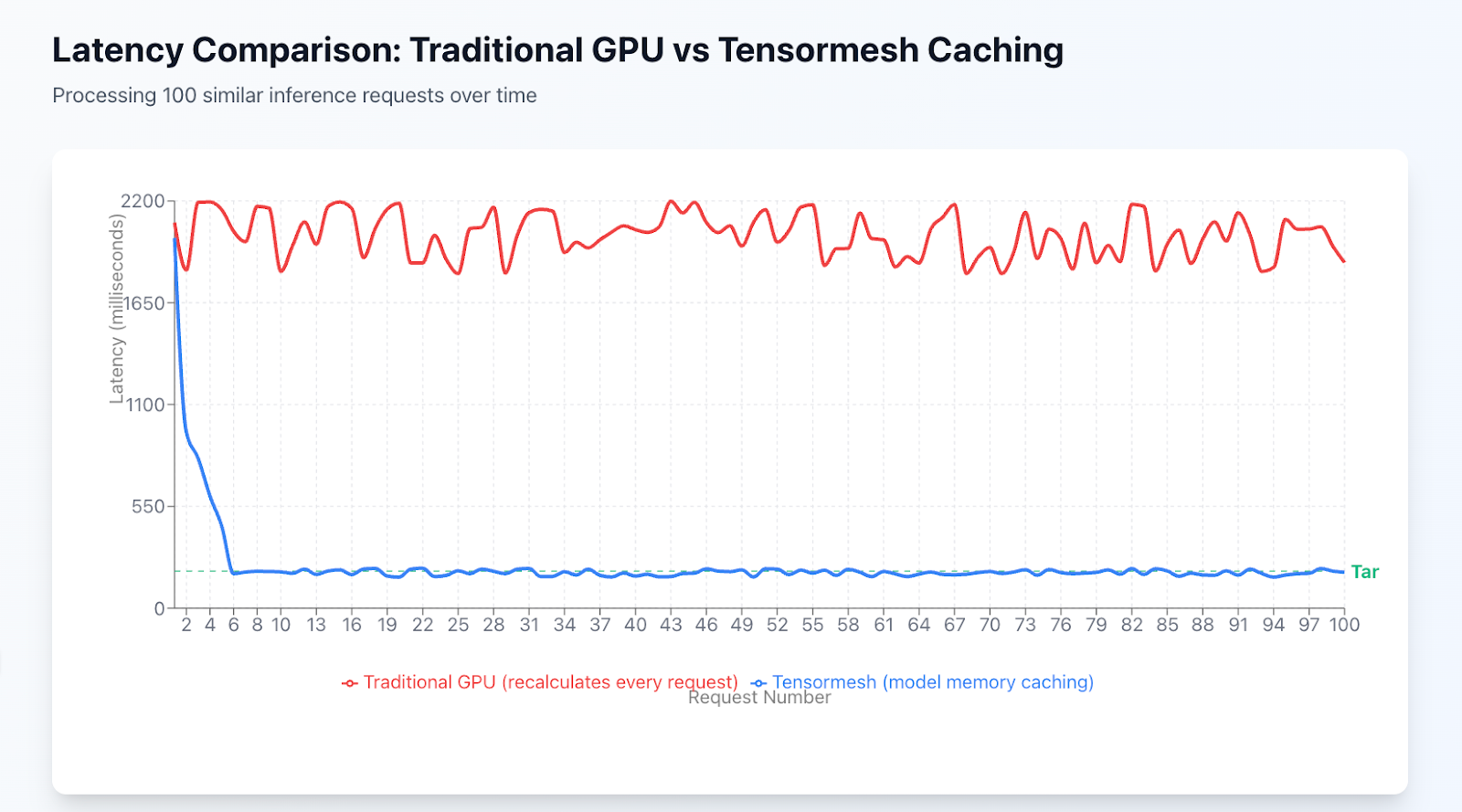
Figure: Latency Comparison Over 100 Requests
This chart illustrates the dramatic latency difference between traditional inference and intelligent model memory caching. Processing 100 similar requests:
- Traditional inference (red line) recalculates everything from scratch for each request, maintaining consistent ~2000ms latency
- Tensormesh with caching (blue line) processes the first request normally, then serves subsequent similar requests from cache at ~167ms driving a 12× improvement
The gap represents wasted time spent on redundant GPU computations that intelligent caching eliminates automatically.
Real-World Applications
Low-latency AI inference enables entirely new categories of applications:
- Interactive Customer Service: AI chatbots must respond with human-like speed to maintain engagement and replace human agents cost-effectively
- Real-Time Fraud Detection: Financial institutions need instant anomaly detection without transaction delays or increased fraud exposure
- Personalized Content Generation: E-commerce platforms need instant recommendations without breaking shopping flow
- Voice Assistants: Conversational AI requires near-instant responses to feel natural and useful
- Autonomous Systems: Self-driving vehicles and industrial robots need split-second decisions for safety
Organizations that solve latency don't just improve existing applications, they unlock new revenue streams impossible with slower systems.
The Strategic Imperative
As AI becomes infrastructure, latency becomes a first-order business concern. Organizations have three options:
- Accept degraded performance and watch competitors capture market share
- Throw hardware at the problem, paying escalating costs for marginal improvements
- Adopt intelligent caching architectures that eliminate redundant work and fundamentally improve economics
The companies that solve latency now will serve more users, deploy more sophisticated models, enter more markets, and build sustainable competitive advantages all while spending less on infrastructure.
The question isn't whether your AI infrastructure can be faster. The question is: can you afford to wait?
Getting Started with Tensormesh
Tensormesh addresses the AI latency crisis through intelligent model memory caching:
- 5-10× cost reduction by eliminating redundant GPU computations
- Sub-millisecond latency for cached query components
- Faster time-to-first-token even for complex, multi-step inference
- Complete observability into cache performance and optimization opportunities
Most teams are running production workloads within hours of deployment.
Ready to eliminate the latency bottleneck? Visit www.tensormesh.ai to access our beta platform, or contact our team to discuss your specific infrastructure challenges.
Tensormesh — Making AI Inference Fast Enough to Matter
Sources
- GigaSpaces:
Amazon Found Every 100ms of Latency Cost Them 1% in Sales - Geeking with Greg:
Marissa Mayer at Web 2.0 - Google 0.5 Second Delay Study - GigaSpaces:
Financial Trading Latency Costs - Nielsen Norman Group:
Response Times: The 3 Important Limits - GlobalDots:
Latency Impact on eCommerce - 53% Abandonment Rate - Retail TouchPoints:
Milliseconds Matter: A 0.1 Second Delay Can Hurt Conversions 7% - GlobalDots:
Walmart Load Time Study - AWS Machine Learning Blog:
Optimizing AI Responsiveness - DigitalOcean:
Low Latency Inference for Real-Time AI Applications - BSO Network:
Why Low-Latency Connectivity Is Vital in the AI Arms Race - WEKA:
Storage is the New AI Battleground for Inference at Scale - Salesforce Engineering:
How Salesforce Delivers Reliable, Low-Latency AI Inference - LMCache Performance Comparison:
https://arxiv.org/pdf/2510.09665











































