Designing AI Infrastructure Products for Developers

Based off an Interview with Katherine Yee, Software Engineer at Tensormesh
AI infrastructure products are built for technical users who arrive with specific goals and high expectations. They want to deploy a model, test an API, understand pricing, compare latency, or validate whether a platform can support production workloads. They are not looking for a long product tour, and they usually will not spend much time figuring out unclear navigation.
That makes UI and UX design in AI infrastructure especially difficult. The product has to expose enough technical detail to earn trust while still helping users move quickly from first login to first successful result. Too much abstraction can make the platform feel vague, while too much complexity can make it feel like it is a black box.
At Tensormesh, this balance shows up in nearly every product decision. The platform has to explain deployments, models, caching behavior, cost, latency, and cache hit rates in a way that feels useful to experienced developers without overwhelming users who are still learning the infrastructure layer.
First impressions matter more in AI infrastructure
AI infrastructure users tend to abandon platforms quickly when the path forward is unclear. The market is also far more competitive than it was a few years ago, which means developers have more inference platforms, model hosting tools, and infrastructure providers to choose from.
A confusing first experience is no longer just a design issue, it becomes a business issue.
That is why onboarding has to do more than look simple. It should help users understand what to do next, why that step matters, and how it connects to the workload they are trying to run. For developer-focused platforms, the first experience should move users toward a real technical outcome as quickly as possible.
New AI metrics need clearer product language
AI infrastructure is still developing its own product language. Traditional cloud dashboards have familiar patterns for cost, storage, throughput, and utilization, but modern AI workloads introduce newer metrics that do not yet have established visual conventions.
For agentic and long-context applications, teams may care about cost per task, time to first subtask, cache hit rate, cached input tokens, and repeated context reuse. These metrics matter because they map more directly to how AI applications behave in production. An AI agent may plan, call tools, reference documents, reuse instructions, and continue across several steps. A coding assistant may repeatedly use the same repository context, tool definitions, and conversation history. In those cases, a simple cost per token view does not explain the full workload.
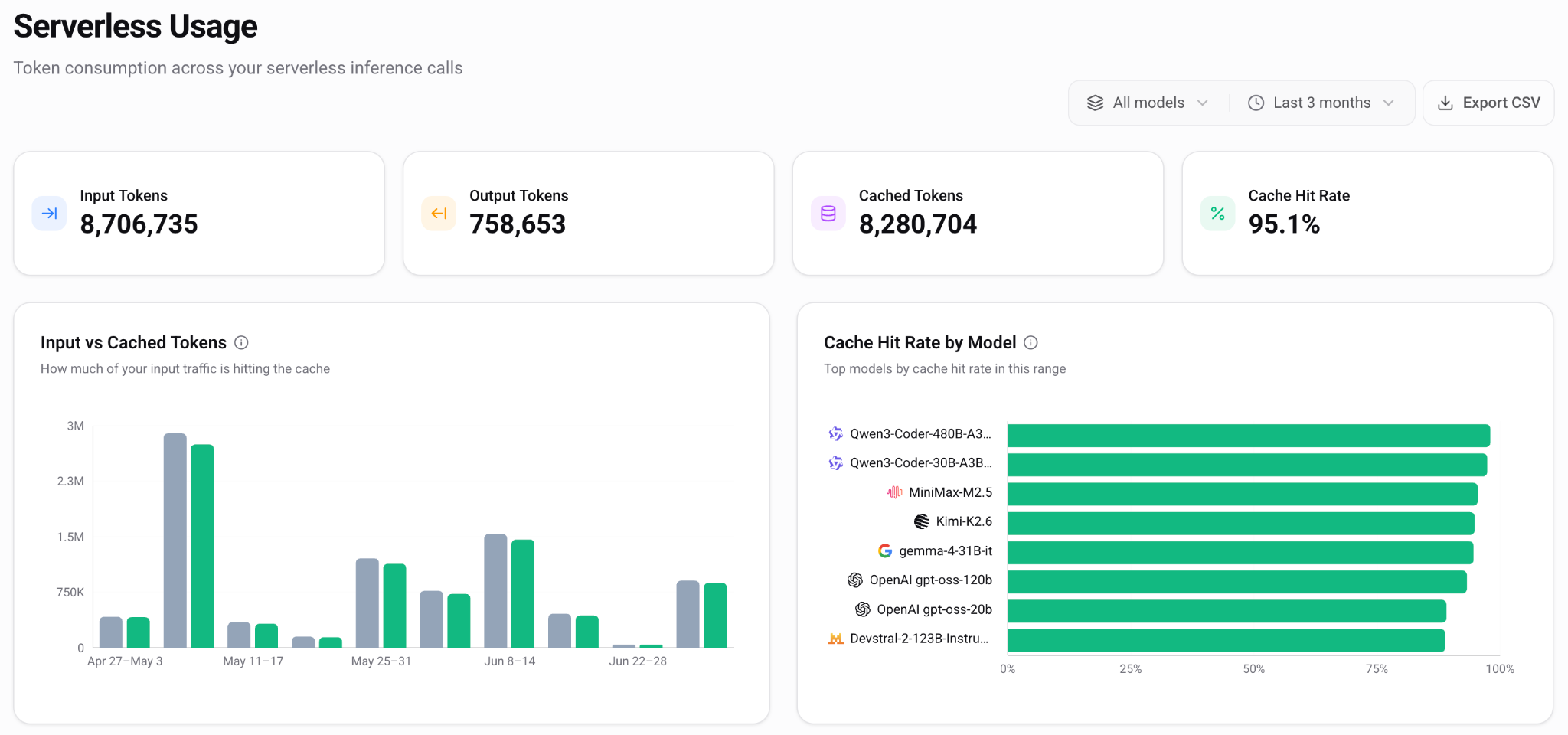
For Tensormesh, this is where context caching becomes central to the product experience. The UI has to show when repeated tokens are being cached, how often cached context is reused, and how that reuse affects cost and latency over time.
Trust comes from concrete numbers
One challenge with caching metrics is that the numbers can look unfamiliar at first. A user may see millions of cached tokens and assume that number maps to a large cost, even when the actual cost impact may be only cents depending on pricing and cache behavior.
That means the product cannot rely on metrics alone. It needs concrete examples, clear documentation, and cost breakdowns that help users understand what the numbers actually mean.
This is especially important for a platform like Tensormesh, where the value depends on showing how repeated context changes inference economics. Users need to see the connection between cache hits, cached tokens, cost per request, and overall workload efficiency.
Backend reality shapes the user experience
AI infrastructure UI cannot be designed separately from the backend. Deployment behavior, autoscaling, model availability, storage limits, and cache lifecycle management all shape what the interface can promise.
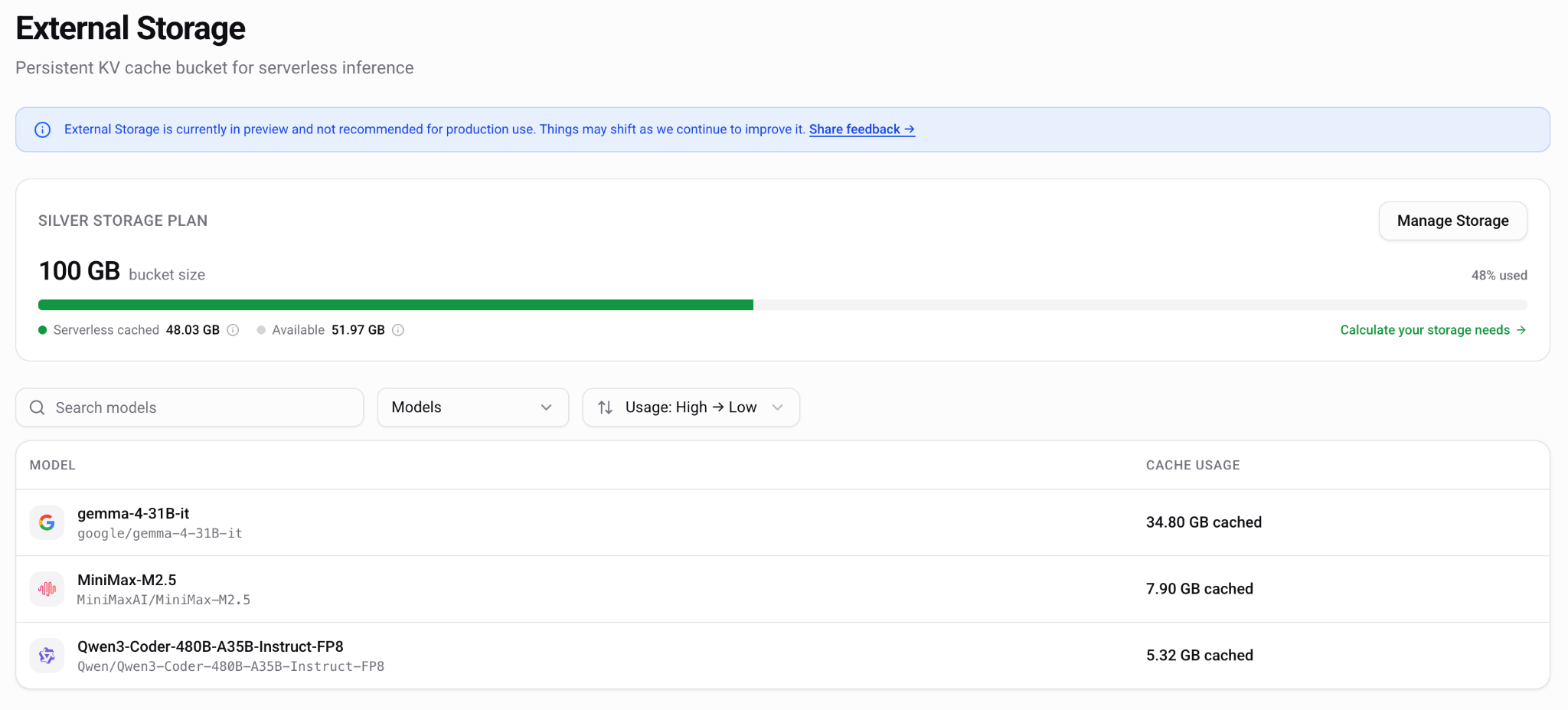
At Tensormesh, product development has required constant iteration between front-end concepts and backend reality. External storage flows needed several mockups before the team aligned on what users should control and what the platform could reliably support. Autoscaling also required the UI to change once the backend behavior became clearer.
Product constraints should be easy to understand
Every infrastructure company has constraints, the question is whether the product explains them clearly.
Tensormesh has had to make decisions around resource constraints, deployment options, model support, and external storage limitations. The recent decision to cut on-demand support is one example. Removing a path can simplify the platform, but only if users can quickly understand which deployment option is now right for them.
The same applies to model support as some competitors may offer broader model catalogs. This means Tensormesh has to be clear about where it is focused. The value is not simply access to every model. The value is caching-accelerated inference for workloads where repeated context drives unnecessary cost and latency.
That positioning should show up inside the product, not just on the website. Instead of relying on broad serverless language, the platform should guide users toward specific use cases where caching matters most, including long documents, coding agents, recurring prompts, tool-heavy workflows, and production applications with repeated context.
Documentation should help users take action
For technical products, documentation is part of the product experience. Tensormesh uses Mintlify to make docs easier to navigate and maintain, with an AI helper to answer user questions. That is useful, but documentation still needs to be built around action rather than long explanations.
A user trying to deploy a serverless model needs a different path than a user trying to understand cache hit rates. A user building an agent needs different guidance than a user evaluating reserved infrastructure. A user trying to understand cost needs real examples, not abstract descriptions.
This is why step-by-step tutorials are so important. Docs explain what a platform does, while tutorials show how to get value from it. For a category like context caching, where many developers are still learning the mental model, tutorials can make the difference between interest and adoption.
Open source helps build confidence
Tensormesh has an important advantage because its work is grounded in LMCache, the open source project behind much of its caching foundation. That matters because trust is hard to earn in AI infrastructure, especially when a platform claims to reduce cost and improve performance.
Open source gives users a way to understand the underlying ideas, follow the community, and see that the product is not a black box. In a crowded market where many providers compete on similar claims around speed, scale, and cost, that transparency is a real differentiator.
The product experience should make that connection clear. Users should be able to understand how open source caching research becomes production infrastructure, and how that foundation translates into measurable value for their workloads.
The best infrastructure UX teaches while users build
Many AI infrastructure users are technical, but that does not mean they already understand every concept in the product. Katherine Yee’s experience at Tensormesh reflects this well. She joined without a background in AI infrastructure and learned through Claude, company research, team meetings, and prior ML and AI fundamentals from Breakthrough Tech and Latitude AI.
That learning path is common. Many strong developers understand AI concepts but still need to learn the infrastructure layer around inference, caching, deployment, and cost optimization.
A strong product experience should support that learning without slowing advanced users down. It should provide clear navigation, useful defaults, contextual explanations, concrete examples, and documentation that connects technical concepts to real workloads.
For Tensormesh, the goal is not to hide the complexity of context caching. The goal is to make it understandable at the moment it matters. Developers should be able to see where repeated context exists, understand how caching improves their workload, and move from evaluation to production without getting lost along the way.












































