Agentic AI Inference Cost: How LLM Agent Loops Break Caching and Drain Your Budget

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
If you are building on top of LLMs, you are probably already aware that caching exists. Anthropic supports prompt caching with a 5-minute default window. OpenAI applies prefix caching automatically on prompts over 1,024 tokens. Frameworks like vLLM offer prefix cache reuse that, in controlled settings, can reach over 90 percent hit rates on general agentic tasks.
The problem is not that caching does not exist, it is that agentic workloads introduce a specific set of conditions that make existing caching fragile, inconsistent, or insufficient at production scale. Dynamic prompt injection, long-horizon sessions, non-prefix reuse patterns, and short cache TTLs all chip away at the savings that caching promises on paper. Understanding exactly where and why existing caching breaks down is the first step toward closing the gap.

What actually happens inside an agent loop
To understand where caching breaks down, you need a precise picture of what your agent is doing at the token level. Take a standard agent running a research task as an example.
On the first call, the model receives your system prompt plus the user task and generates a plan. The input is modest and the cost is predictable. On the second call, your orchestration layer stacks the model output from the prior step along with the result from a tool invocation. The model now attends over the full accumulated context before generating its next action. Neither your system prompt nor the first reasoning step has changed. The model recomputes attention over all of it regardless, unless that prefix is cached and still within the cache window.
By the tenth call, the model is attending over nine prior reasoning steps, nine tool results, and your original system prompt on every single forward pass. In a typical agentic session, upward of 95 percent of the tokens being processed at step 10 are identical to what was processed at step 9. The core challenge is not the absence of caching. It is that agentic workloads impose conditions, including dynamic prompts, long sessions, and mid-sequence reuse, that existing caching mechanisms were not designed to handle reliably at scale.
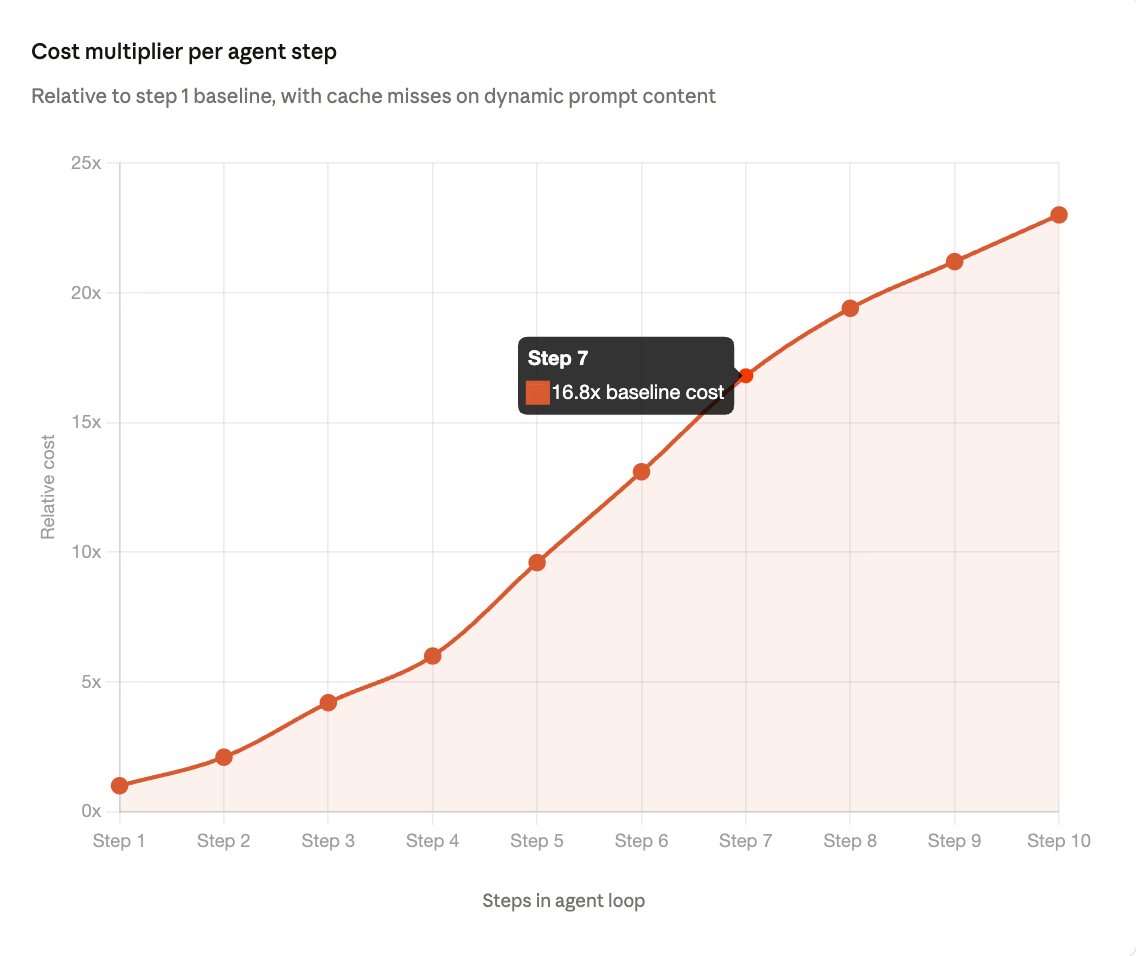
Token-level cost breakdown across a 10-step loop
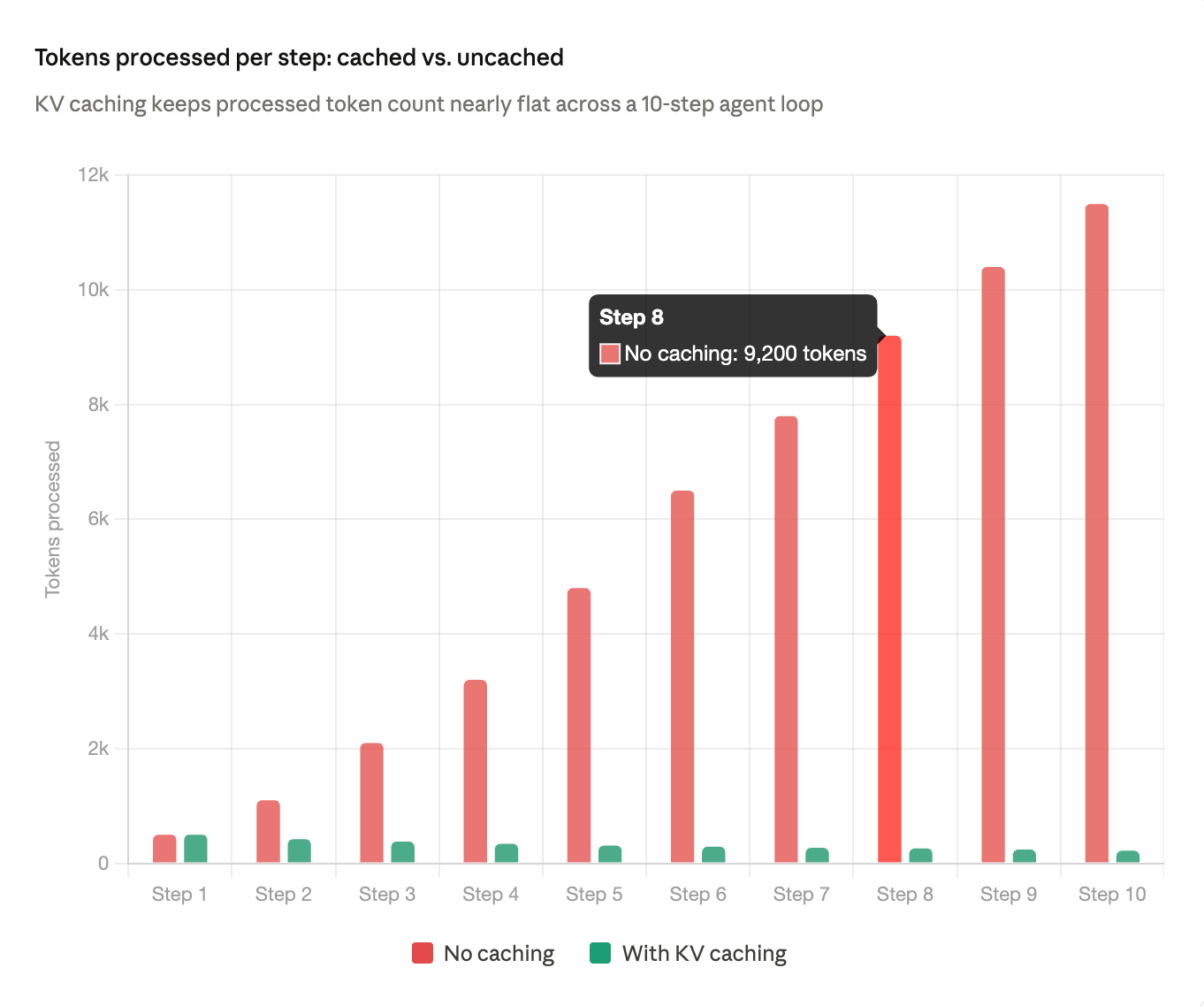
The table below models a typical research agent with a 500-token system prompt, tool results averaging 600 tokens each, and concise model outputs. Even at this conservative scale, the redundancy problem becomes severe within a handful of steps, particularly when any part of the system prompt changes between turns.

At step 10, your model is processing 11,500 input tokens to act on 200 tokens of new information. The useful signal density has dropped to under 2 percent of the total input. A well-functioning cache should absorb most of that repeated context. In practice, three common patterns prevent it from doing so.
Three patterns that cause caching to break down in agentic settings
1. Dynamic system prompts that invalidate prefix caches
Many agent frameworks inject dynamic values like timestamps, user IDs, or session configuration directly into the system prompt at runtime. A single character difference in the system prompt invalidates the prefix cache entirely, forcing a full recompute on every subsequent step. This is a solvable architectural problem, but it requires deliberate prompt structure that most frameworks do not enforce by default.
2. Cache TTLs that do not fit long-horizon session lengths
Provider-level prompt caching typically operates on a 5-minute TTL window, which works well for short, high-frequency tasks. For long agent sessions that run for tens of minutes or resume after a pause, that window expires mid-session and previously cached prefixes are recomputed from scratch. At production scale, short-lived caching leaves a significant portion of potential savings.
3. Non-prefix reuse patterns that fall outside standard caching scope
When a model re-reads eight tool results from prior steps to process the ninth, only the initial system prompt qualifies as a cacheable prefix. The intermediate tool outputs, which represent the largest share of context growth, are re-processed in full on every call. Closing this gap requires semantic caching at the tool call level, which sits outside what standard provider APIs currently offer.
What persistent and session-aware caching looks like
The gap in existing caching is not the concept itself. It is the persistence, session awareness, and storage backing needed to make caching work reliably for the access patterns that agentic workloads create.
Persistent KV cache storage writes cached key-value states to durable storage rather than holding them in GPU memory with a short TTL. This allows cache reuse across sessions that resume after a pause and across time horizons that exceed standard provider cache windows, with cost reductions in the 41 to 80 percent range consistently reported on production agentic workloads.
Session-scoped memory management tracks context growth at the session level rather than the request level. A session-aware layer compresses prior reasoning steps and retains only what is relevant to the current action, keeping the active context lean and reducing the surface area for cache misses.
Semantic tool call caching detects when an agent issues a tool call that is functionally equivalent to one made earlier in the session and returns the stored result instead of re-executing. This captures reuse patterns that standard prefix caching misses entirely because it operates on query content rather than raw token prefixes.
Standard caching vs. infrastructure-level caching
To make the distinction concrete, here is how provider-level prompt caching and infrastructure-level KV caching compare across the dimensions that matter most for production agentic workloads.

How to audit your own agent for cost efficiency
Before optimizing your infrastructure, measure where your current caching is and is not working. These four questions give you a quick diagnostic on any agentic workflow.
What is your actual cache hit rate per step? Most providers expose cache hit metrics in their API responses. A hit rate below 70 percent on steps 3 through 10 is a strong signal that your prompt structure is causing frequent cache invalidation.
Is your system prompt static or dynamic? Audit every value injected at runtime and move dynamic values into the user turn or a dedicated context block wherever possible to preserve the static prefix.
How large are your tool outputs, and are they being reused? Log the average token count per tool result and track how often semantically similar queries are issued across steps. High repetition is a clear signal that semantic tool call caching would provide meaningful savings.
What is your average session length relative to your cache TTL? If your sessions regularly exceed your provider cache window, you are paying full price for reprocessing that should have been cached. Move to a caching layer with configurable or persistent TTL if restructuring sessions is not an option.
Caching is no longer optional at production scale
The existence of caching in the inference stack is well established. What is still catching teams off guard is how quickly the conditions of production agentic workloads erode the savings that caching should deliver. Dynamic prompts, long sessions, and mid-sequence reuse patterns all push against the boundaries of what provider-level caching was designed to handle.
The teams that are winning on inference cost are not just using caching, they are using caching that is persistent, session-aware, and built around the actual access patterns of the workloads they are running. That is the gap Tensormesh was built to close, with an inference layer that treats KV cache persistence and session-level memory management as core infrastructure rather than optional add-ons.
See how Tensormesh handles agentic workflows
Take a deep dive into Tensormesh documentation
Sources
1.Lim et al. "Don't Break the Cache: An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks." arXiv, January 2025. arxiv.org/pdf/2601.06007
2.Anthropic. "Prompt Caching." Claude API Documentation, 2026. platform.claude.com/docs/en/build-with-claude/prompt-caching
3.Xu, Khaira, Singh. "KV Cache Optimization Strategies for Scalable and Efficient LLM Inference." Dell Technologies, arXiv, March 2026. arxiv.org/pdf/2603.20397
4.Zhang et al. "ARKV: Adaptive and Resource-Efficient KV Cache Management for Long-Context Inference in LLMs." arXiv, March 2026. arxiv.org/pdf/2603.08727
5.DigitalOcean. "Prompt Caching for Anthropic and OpenAI Models: Building Cost-Efficient AI Systems." DigitalOcean Blog, March 2026. digitalocean.com/blog/prompt-caching-with-digital-ocean
.png)














































