Beyond Prefix Caching: How Non-Prefix Caching Achieves 25x Better Hit Rates for AI Agents

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
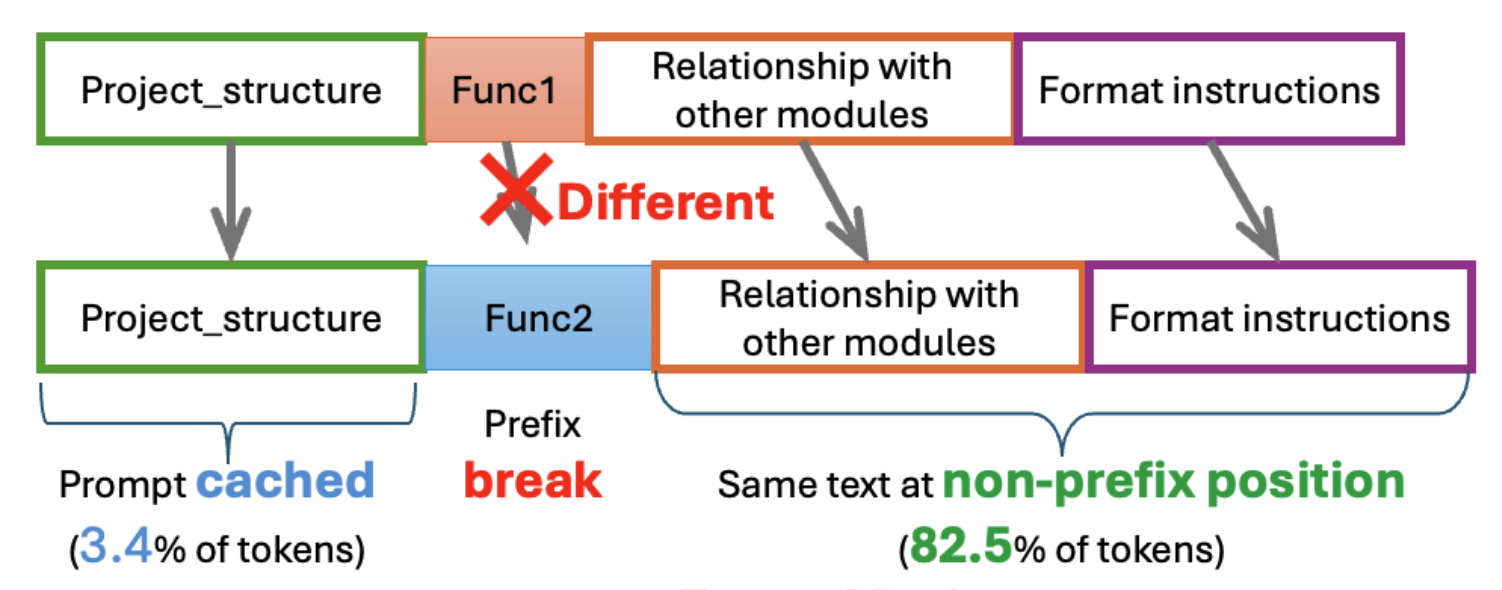
RepoAgent prompt caching only gives you 3.4% token hit rate, however, 85.9% of the prompts are reused (as non-prefix). Our technique, CacheBlend, enables non-prefix prompt caching and helps improve cache hit rate by 25x (3.4% to 85.9%)
Motivation
If you can only pick one metric to optimize in production-scale agents, what would that metric be? According to Manus, the single most important metric is the prompt caching hit rate.
With recent agents, we start to find that prompt caching hit rate is really low even though these agents logically are massively processing existing information in LLM prompts.
To understand why prompt caching does not appear for these agents, we dive into one example: RepoAgent, an agent that generates documentation for your github repository.
Workflow of RepoAgent
RepoAgent processes code objects in topological order based on their dependencies. This ensures that when documenting a function, the documentation for all functions it calls is already available.

The solid arrows represent parent-child relationships (containment), while the dashed arrows represent reference relationships (calls/dependencies).
RepoAgent uses these relationships to:
- Build a dependency graph
- Compute topological order
- Generate documentation bottom-up (leaf nodes first)
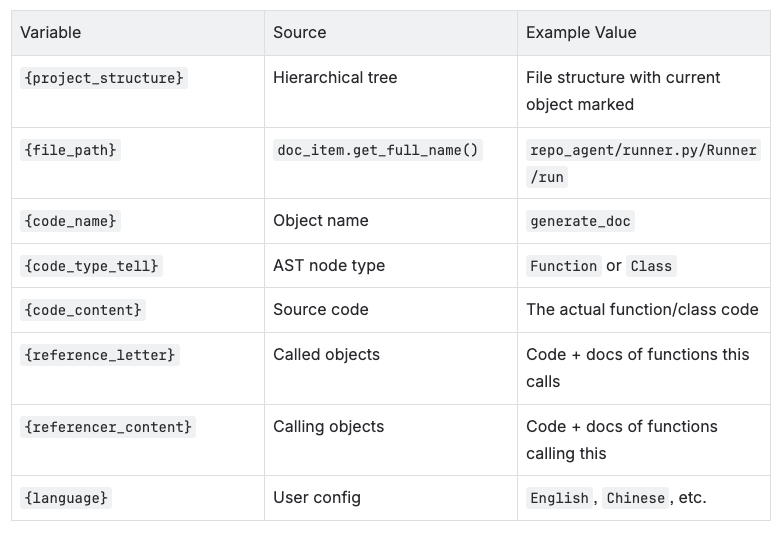
How RepoAgent Prompts Are Generated
Generated based on a the following template:

If you are interested in the concrete detail on what are these variables like code_type are:
Prompt Cache Hit Rate Analysis
The prompt template above directly causes low prompt cache hit rate. The key reason is that prompt caching requires the prompt to be prefix, but in RepoAgent, the same text will move position in the prompt, making them non-prefix.
Say both Func_1 and Sub_Func_2 call Sub_Func_1 (see dashed arrows in topo.svg). When generating documentation for each, Sub_Func_1's code appears in the {reference_letter} section—but at different positions:
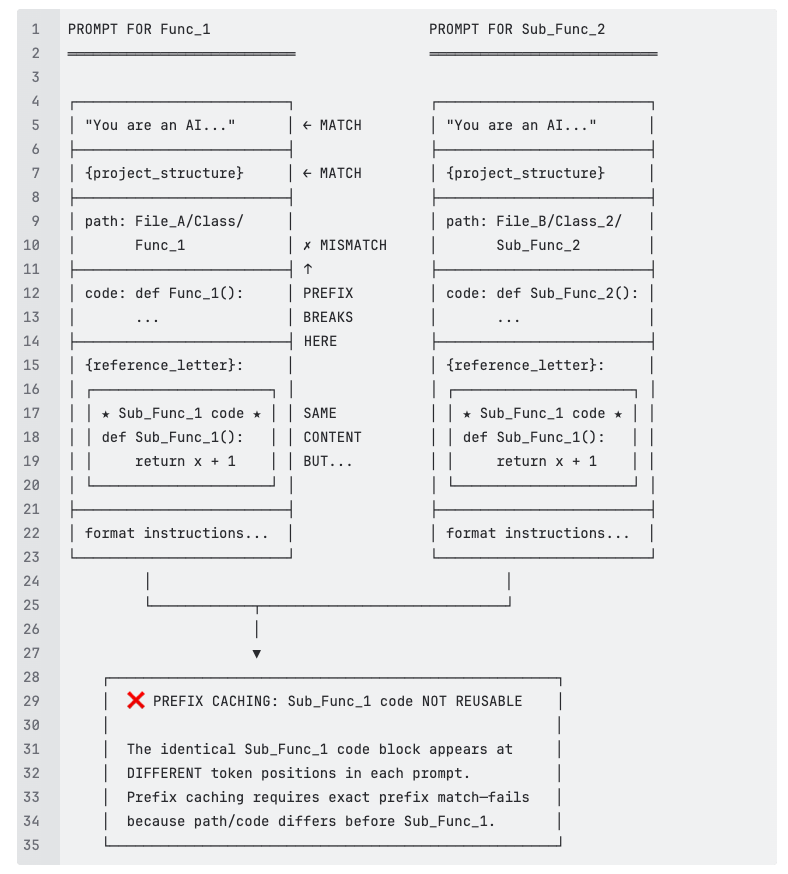
We summarize the root causes of why prompt caching fails.
- Early Dynamic Variables: {project_structure} and {file_path} appear within the first 200 characters, immediately breaking prefix alignment
- Unique Code Content: Every request documents a different function/class with unique source code
- Variable Reference Context: The {reference_letter} and {referencer_content} sections vary based on each object's call relationships
- Topological Processing: Objects are processed by dependency order, not file proximity, so consecutive requests often document unrelated code
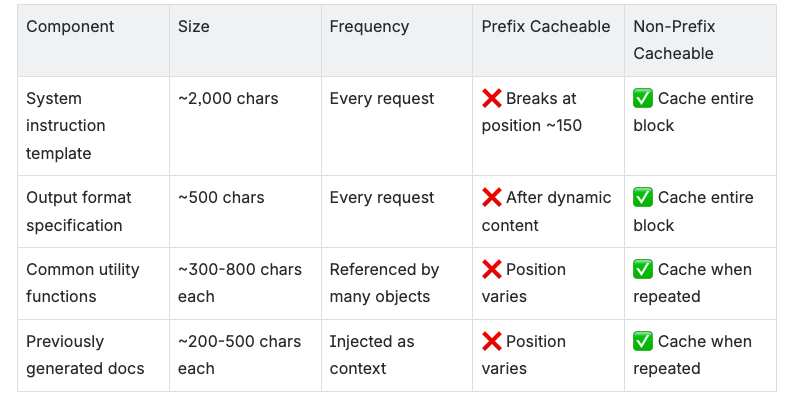
The Non-Prefix Advantage
Unlike prefix caching, non-prefix prompt caching can match and reuse any contiguous block of tokens, regardless of the position. This fundamentally changes what can be cached:

Cacheable Components in RepoAgent
Empirical Results
LMCache benchmarks demonstrate the dramatic improvement:
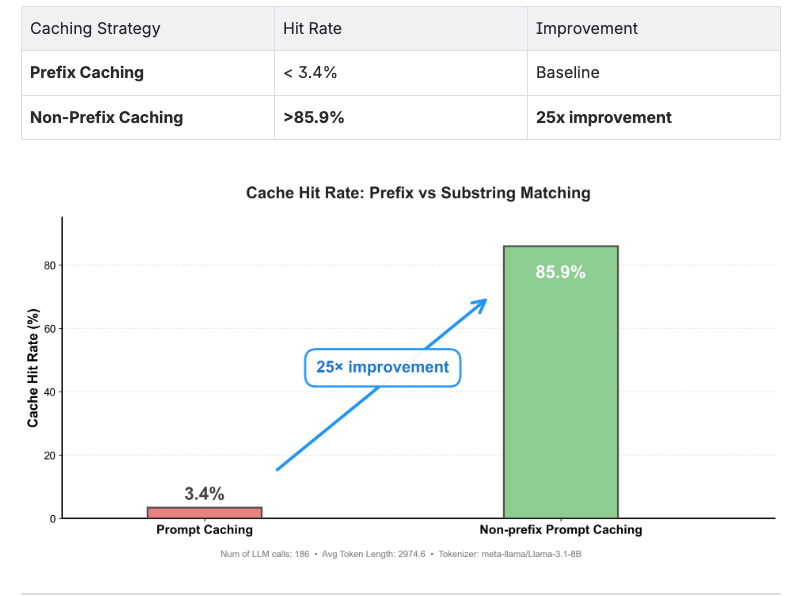
CacheBlend helps you achieve non-prefix prompt caching.
We have non-prefix prompt caching built at Tensormesh, using our technique CacheBlend.
Please contact us if you are interested in trying CacheBlend on your workload!
References
- RepoAgent GitHub Repository
- LMCache Agent Trace Benchmarks
- RepoAgent Paper (arXiv:2402.16667)
- LLM Agent Trace Viewer












































