LMCache ROI Calculator: When KV Cache Storage Reduces AI Inference Costs

Large language models (LLMs) are transforming how we build applications, but their computational costs can be staggering: it already takes $3 for LLM to process just one single NVIDIA annual report using OpenAI API, not to mention processing documents and texts from thousands of users per second.
But what if you could cache those text-processing computations (the prefill computations) and reuse them? That's the promise of KV caching systems like LMCache. The question is: when does the cost of storing cached data actually save you money compared to recomputing everything from scratch?
The Economic Challenge of KV Caching
KV caching systems, such as LMCache, allow you to save your prefill computation if part of the text has been processed previously, by saving and reusing KV caches (the intermediate activation tensors of LLMs). But this essentially saves computation at the cost of extra storage bills.
This is where precise TCO (Total Cost of Ownership) analysis becomes critical. We built the LMCache TCO Calculator to help teams answer a deceptively simple question: “What hit rate justifies expanding my cache with storage?"
Breaking Down the Costs
GPU Computation Costs
When you run inference without caching, every token in your prompt must be processed through the model's attention layers. For large models like Llama 70B or Qwen 480B, this means:
- Small models (8B-30B parameters): ~30,000 tokens/second/GPU
- Large models (70B+ parameters): ~2,500 tokens/second/GPU, typically requiring 8+ GPUs working together
At $2/hour per GPU, processing even moderate amounts of cached data can add up quickly. For a big model deployment, you're looking at $16/hour just for the GPU fleet.
Storage Costs
KV caching can use two (or more) storage tiers:
Tier 1 (RAM): Fast access for hot data, but expensive. While some deployments might allocate this from existing GPU or server RAM at near-zero marginal cost, dedicated cache RAM has real infrastructure costs.
Tier 2 (Attached or Shared Storage): Higher capacity, lower cost. Think S3 Express or fast network storage at ~$4,000-5,000 per TB over 3 years. This is where you store less frequently accessed cache entries.
The key insight: for 1080 GB of cache storage (80 GB Tier 1 + 1000 GB Tier 2) on Tier 2 alone, you're paying roughly $0.15/hour or ~$4000 over three years.
The Speed Advantage
Here's what makes caching compelling: cache retrieval is dramatically faster than prefill. Our calculator uses a 10x speedup ratio, meaning:
- Prefill: Process 1,000 tokens from scratch
- Cache hit: Retrieve the same 1,000 tokens 10x faster
This isn't just about saving money, it's about response time and user experience. Faster inference means better product performance.
Understanding Break-Even Analysis
The break-even point answers: "What percentage of requests need to hit the cache for the system to pay for itself?"
With our default configuration (Big model, $2/GPU/hour, 8 GPUs, 100GB tier 2 storage, a minimal storage cost), the break-even hit rate is remarkably low: ~1.06%.
What does this mean in practice?
- Over 3 years (26,280 hours), you need roughly 280 cache hits to justify the storage investment
- That's about one cache reuse every 94 hours
- Or roughly 2-3 times per week for a specific cached prompt
This surprisingly low threshold means KV caching can be economically viable even for workloads with relatively low reuse rates.
Real-World Scenarios
High-Reuse Workload: Documentation Assistant
Imagine an AI assistant that answers questions about your company's technical documentation. Common questions arise repeatedly:
- "How do I configure authentication?"
- "What's the API rate limit?"
- "Explain the deployment process"
With even 10% of queries hitting cached prompts and a terabyte of cache storage, you're saving ~$33,000 over 3 years on a single 8-GPU deployment. The storage cost? About $4000.
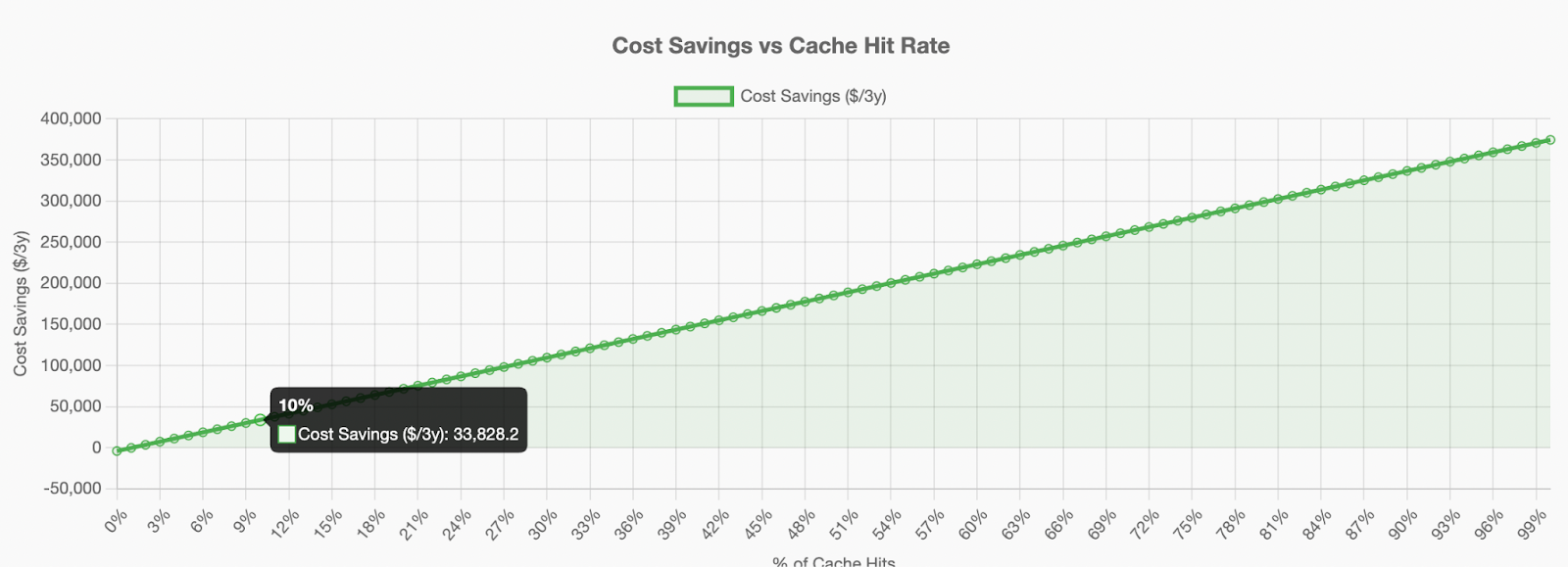
On a fully utilized system, 1TB of Storage becomes relevant as soon as the cache is used by more than 1.06% of the requests
Medium-Reuse Workload: Code Review System
A coding assistant that reviews pull requests might cache:
- Common coding patterns and style guidelines
- Frequently referenced API documentation
- Standard code review checklists
Even with a 5% cache hit rate (one in twenty queries benefits from cached context), you're still saving over $18,000 against minimal or no storage costs.
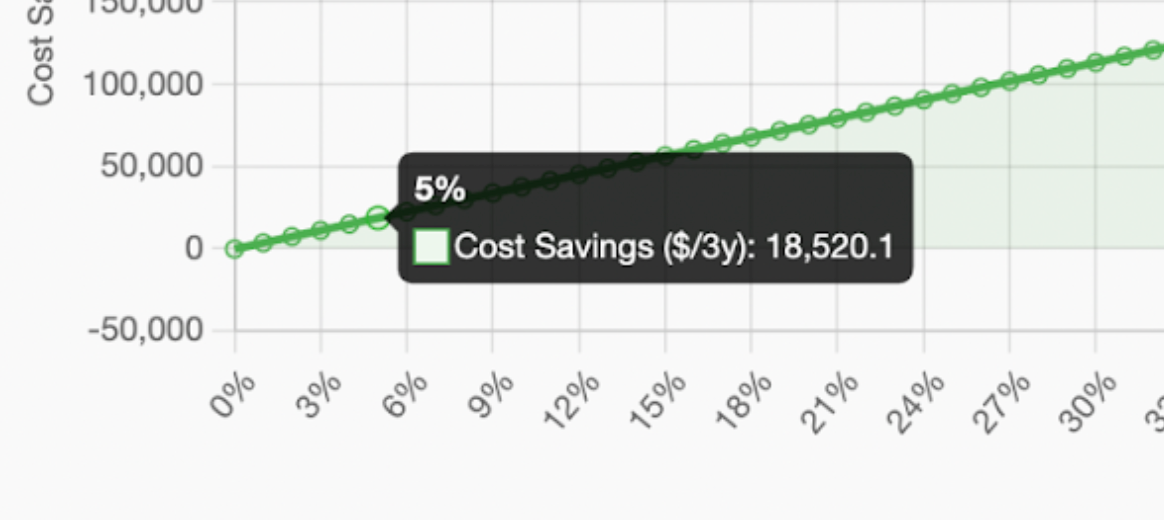
Low-Reuse Workload: Unique Queries
Not every workload benefits. If your application processes truly unique inputs every time, like analyzing novel documents with no recurring patterns, caching may not justify itself. At 1% hit rate, you're barely breaking even.
Using the Calculator
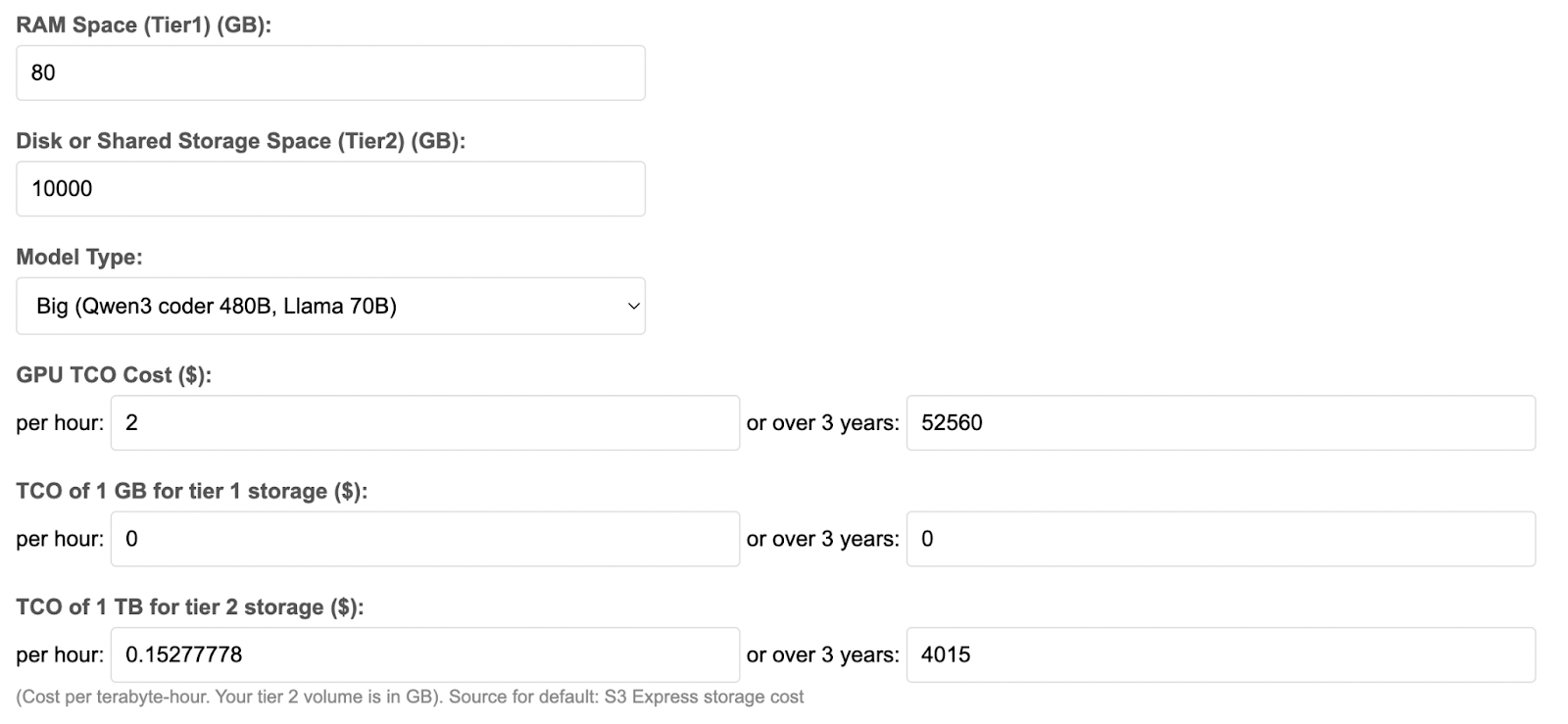
The LMCache TCO Calculator helps you model your specific scenario:
- Define your cache size: How much RAM and disk storage will you allocate?
- Choose your model: Small (8-30B), Sparse (Deepseek-style), or Big (70B+)
- Input your costs: GPU TCO and storage costs per GB/TB
- See your break-even point: The minimum cache hit rate needed to justify the investment
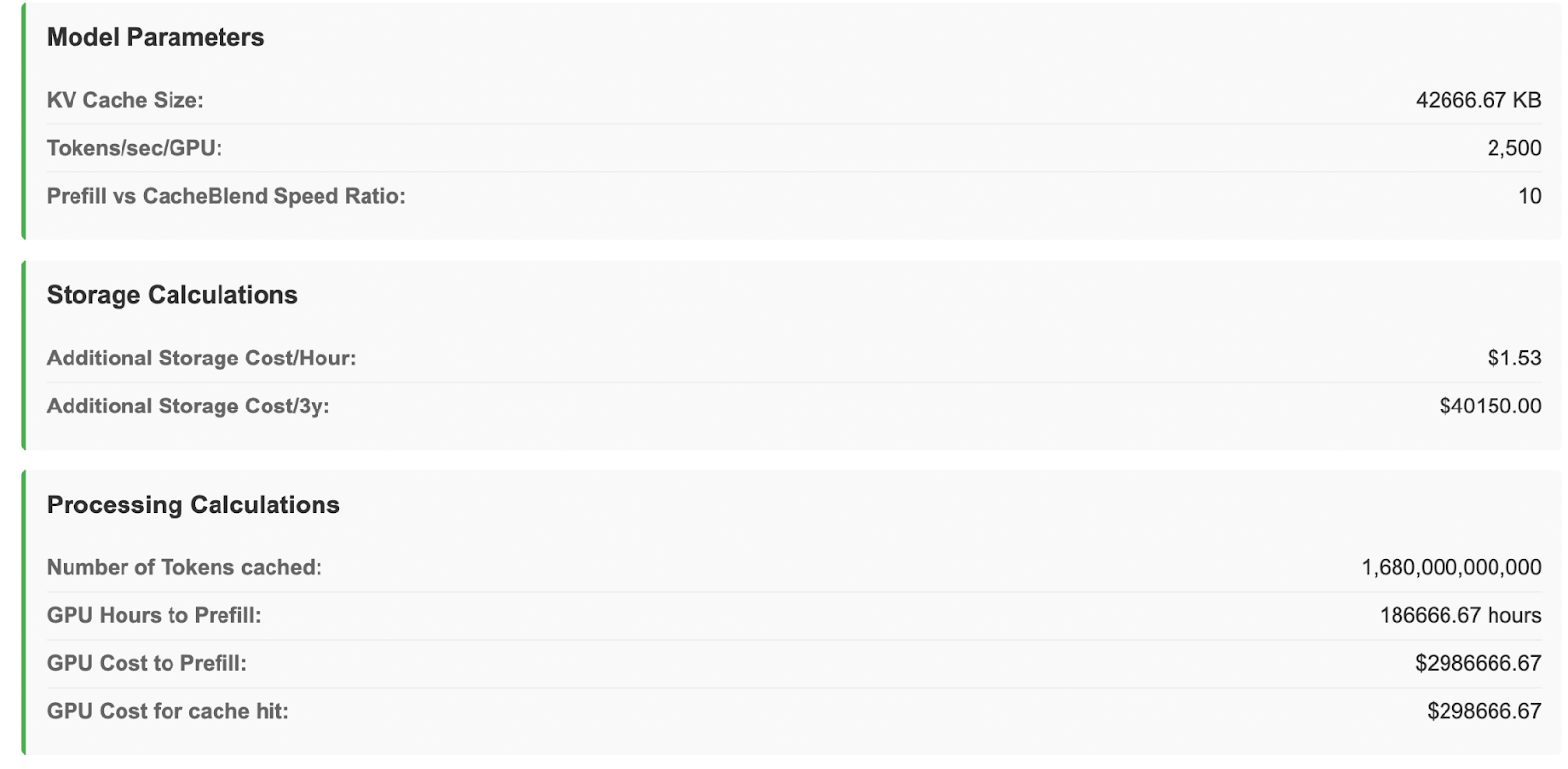
The calculator provides a detailed breakdown:
- Number of tokens you can cache
- GPU hours saved per cache hit
- Storage costs over 3 years
- Cost savings chart across different hit rate scenarios
Key Insights from the Model
1. Storage is cheap compared to computation
For most deployments, Tier 2 storage costs are negligible compared to GPU expenses. The 1 TB of Tier 2 storage in our default configuration costs ~$4000 over three years, while the GPU fleet costs ~$420,000 over the same period.
2. Model size dramatically affects economics
Large models requiring 8 GPUs have higher baseline costs, but this actually makes caching MORE attractive. The break-even threshold drops because you're saving 8x the GPU cost on each cache hit.
3. Speed matters beyond cost
Even if you break even on pure dollar costs, the 10x speed improvement on cache hits means better user experience, higher throughput, and potentially more revenue per GPU.
The Bottom Line
KV caching represents a fundamental shift in how we think about LLM inference costs. Instead of treating every inference operation as a clean slate, we can build systems that learn from past computations and reuse that work.
The economics are compelling: with break-even thresholds as low as 1%, even modest reuse patterns can translate to five or six-figure savings over a typical 3-year infrastructure lifecycle. For high-traffic applications with recurring patterns, the case is even stronger.
The LMCache TCO Calculator gives you the tools to model your specific scenario. Plug in your numbers, understand your break-even point, and make an informed decision about whether KV caching makes sense for your workload.
Try It Yourself
Ready to calculate your potential savings? Visit the LMCache ROI Calculator and model your specific deployment.
Want to use LMCache with no hassle? Try our Tensormesh App which will optimally configure your models for you and will show you your savings in real time.
We are giving you $100 of GPU time to try it out, no credit card needed!
Have questions about the model or want to discuss your specific use case?
Reach out to our team to learn more about implementing efficient KV caching in your infrastructure.
The LMCache TCO Calculator is built by Tensormesh to help teams make informed decisions about LLM infrastructure investments. All calculations are based on industry-standard pricing and performance metrics, but your actual results may vary based on specific implementation details.




























