


Why the caching strategy you choose for memory-augmented LLM agents could make or break your GPU economics at enterprise scale
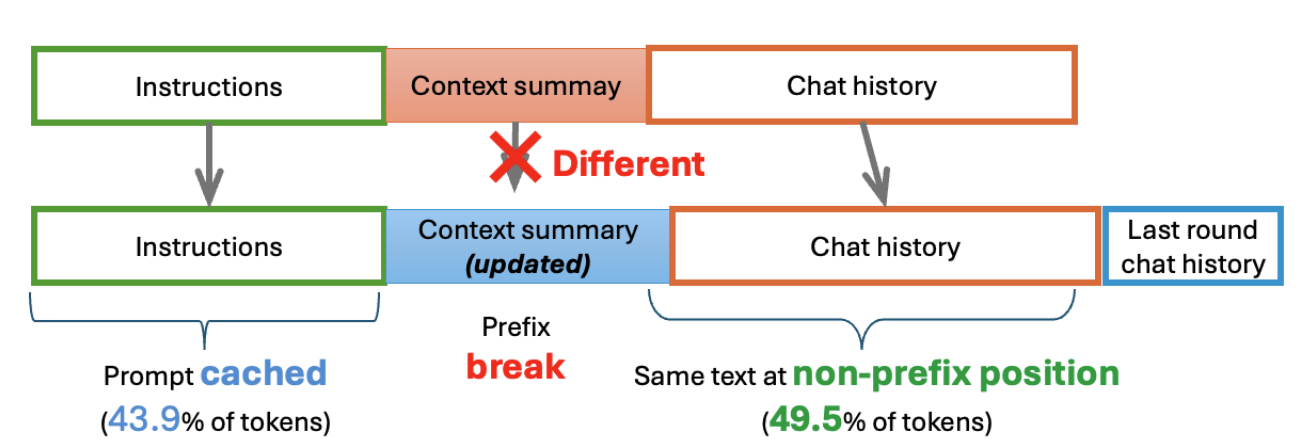
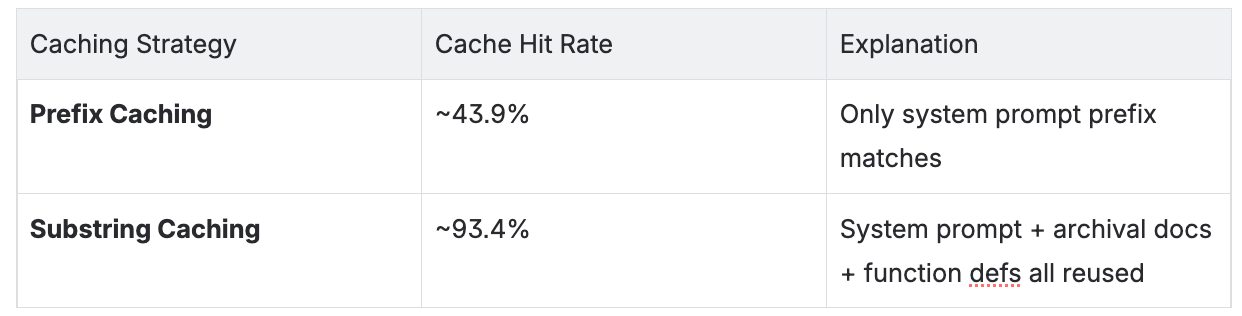
MemGPT's dynamic memory architecture structurally breaks prefix caching — the default optimization strategy for LLM inference. The result: prefix caching only achieves a ~43.9% hit rate on MemGPT workloads, leaving more than half your pre-computed prefill un-reused. Tensormesh's non-prefix caching solves this at the architecture level, achieving ~93.4% cache hit rate on the same workloads. For enterprises running memory-augmented agents at scale, this is the difference between profitable and unsustainable GPU economics.
Your GPU Bills Are Higher Than They Should Be
If your team is deploying memory-augmented LLM agents in production — customer support bots with persistent context, AI research assistants, or long-running document analysis pipelines — there's a good chance you're significantly recomputing the same tokens over and over again.
The reason isn't your model choice or your infrastructure provider. It's your caching strategy.
Most AI infrastructure teams default to prefix caching for KV cache optimization. It's the standard approach, it works well for typical chat usage, and it's built into most serving frameworks. But for memory-augmented agents like MemGPT, or for RAG, prefix caching fails structurally — and the cost shows up directly in your GPU utilization metrics and your inference bill.
Consider a financial services firm running 50 concurrent MemGPT agents for client advisory workflows. Each session averages 16,000 tokens of context. With prefix caching, ~43.9% of those tokens get reused — the rest are recomputed from scratch on every turn. At scale, that's tens of thousands of unnecessary prefill operations per hour. With substring caching, that hit rate climbs to ~93.4% — cutting wasted compute by more than half and bringing inference costs down proportionally.
This post explains exactly why prefix caching breaks for MemGPT, what non-prefix caching does differently, and what it means for your production deployment.
Understanding MemGPT's Memory Architecture
To understand why caching breaks, you first need to understand what makes MemGPT's architecture fundamentally different from a standard LLM application.
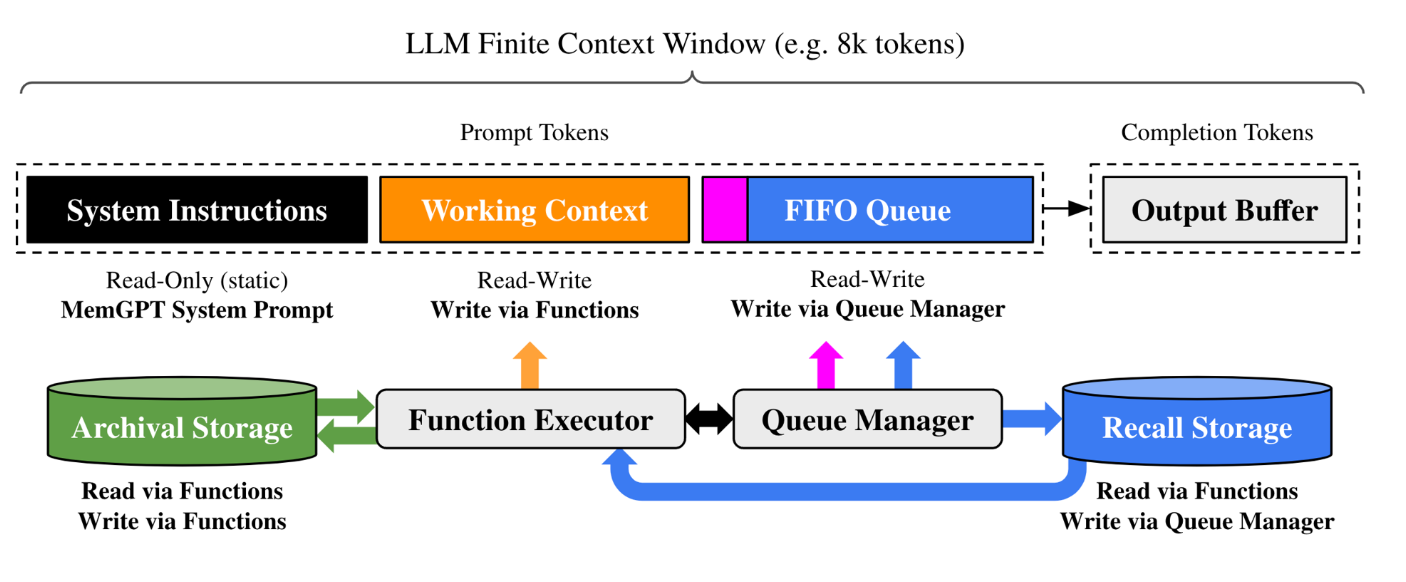
MemGPT treats the LLM context window the way an operating system manages virtual memory, allowing agents to maintain persistent state, recall past conversations, and retrieve stored documents far beyond what fits in a single context window. This makes it powerful for enterprise use cases that require long-running, stateful agent sessions.
The architecture has three layers that work together:
1. LLM Context Window

2. External Storage Systems
- Archival Storage: Long-term memory for facts, documents, and persistent information — retrieved via semantic search
- Recall Storage: Searchable history of past conversations — surfaced when contextually relevant
3. Middleware Components
- Function Executor: Handles read/write operations to Archival Storage and Working Context
- Queue Manager: Controls FIFO eviction policy and writes to Recall Storage
This architecture is what enables MemGPT's persistent memory capabilities. It's also precisely what makes prefix caching fail.
Why Prefix Caching Fails: The Structural Mismatch
Prefix caching works by storing the KV (key-value) states of a prompt's beginning and reusing them when a new request shares the same prefix. For standard chat with a fixed system prompt, this is highly effective — the system prompt never changes, so it's cached once and reused indefinitely.
MemGPT's architecture breaks this assumption in three distinct ways:
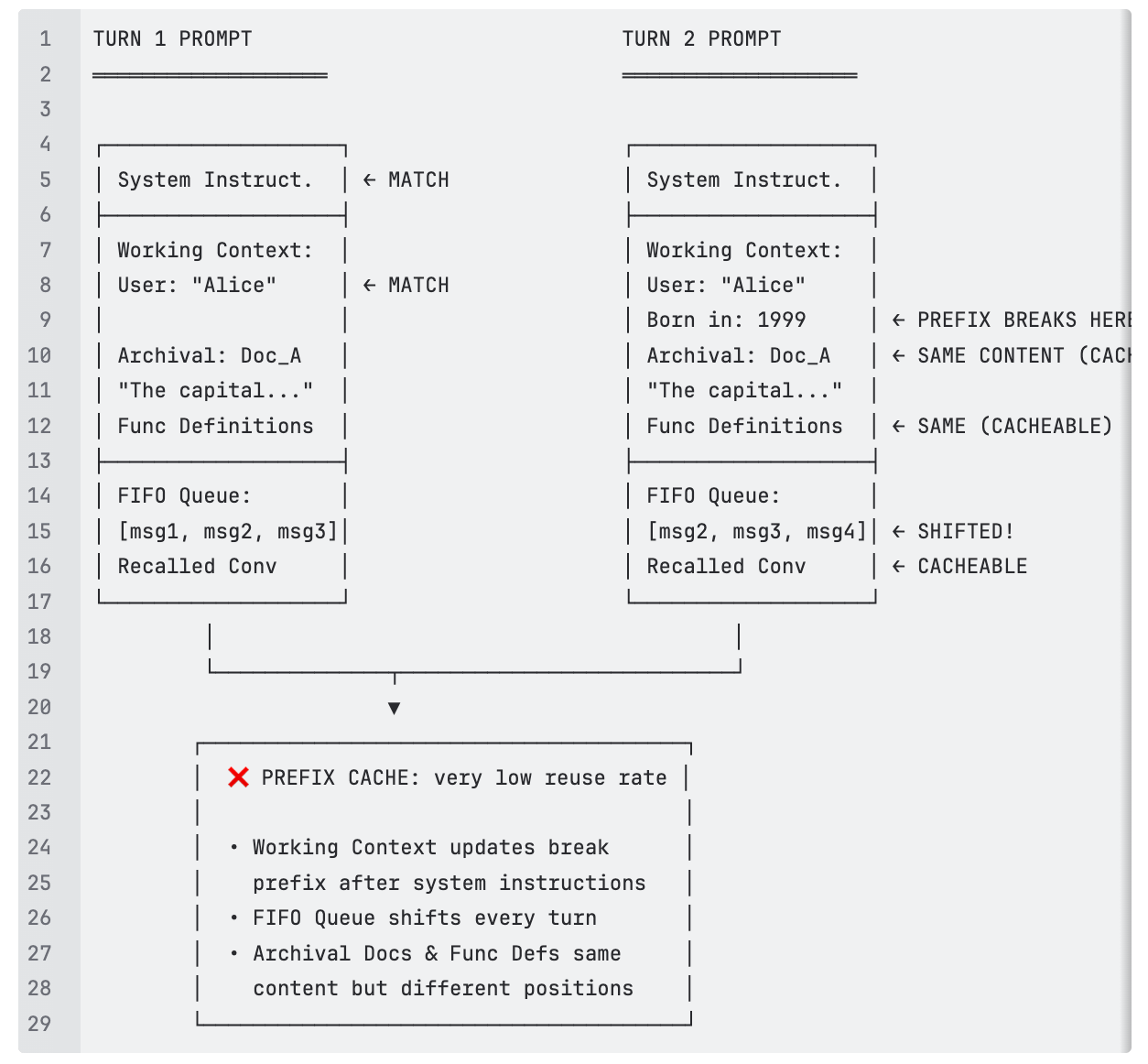
Failure Mode 1: Working Context Mutations
The Working Context section sits immediately after System Instructions in the prompt. When an agent calls core_memory_replace() or core_memory_append() to update user or persona information, the content at that position changes. This breaks the prefix at exactly the point where the largest cacheable blocks — archival documents and function definitions — begin.
The cruel irony: the content you most want to cache sits downstream of the content that keeps changing. Prefix caching can't reach it.
Failure Mode 2: FIFO Queue Shifts on Every Turn
The FIFO Queue holds recent conversation history. Every new user message pushes the oldest message out of the queue. This means the token sequence after System Instructions is different on every single turn — a structural, unavoidable prefix break that happens regardless of whether anything else in the prompt changes.
Failure Mode 3: Variable Archival Retrieval Positions
When the agent retrieves documents from Archival Storage, those documents are inserted into the prompt at positions that depend on the current queue length. The same document retrieved on turn 3 versus turn 7 appears at a different token position. Prefix caching requires identical position — so even repeated retrievals of the same content produce cache misses.
Key takeaway: In a typical MemGPT session with a ~16,000 token context window, prefix caching can only reliably reach the static System Instructions (~2,000 tokens). Everything else is recomputed from scratch on every turn. Measured cache hit rate: ~43.9%. This is not a tuning problem. It's an architectural incompatibility.
Non-prefix Caching: Matching Content, Not Position
Unlike prefix caching, non-prefix (or block) caching matches any contiguous block of tokens regardless of where it appears in the prompt. For MemGPT's architecture, this is transformative. The content that keeps shifting position across turns — archival documents, function definitions, recalled conversations — is still the same content. Non-prefix caching recognizes that and reuses it.
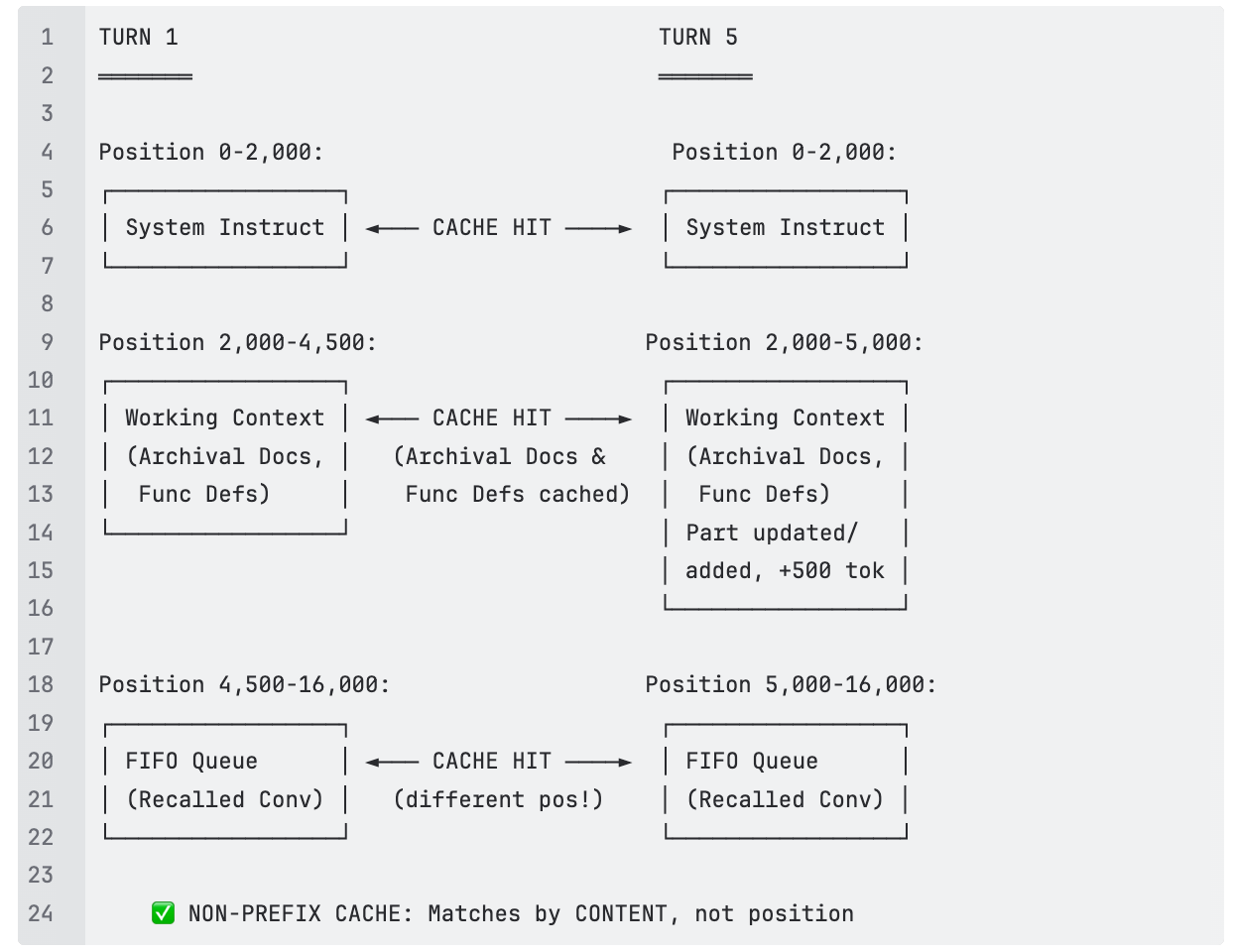
The token math for a ~16,000 token MemGPT prompt:
Prefix caching: System Instructions + partial Working Context = ~3,250 tokens cacheable. Theoretical coverage ~20%. Measured hit rate: ~43.9%.
Non-prefix caching: System Instructions + Archival Docs + Function Defs + Recalled Conversations = ~15,500 tokens cacheable. Only ~500 tokens of genuinely new queue content missed. Theoretical coverage 95%+. Measured hit rate: ~93.4%.
Empirical Validation: LMCache MemGPT Benchmark
The theoretical analysis is confirmed by LMCache MemGPT benchmark results measuring cache performance on production-representative agent traces using meta-llama/Llama-3.1-8B with 20 LLM calls and an average token length of ~21,882 tokens per session.

Observed Cache Performance
What This Means for Your Enterprise Deployment
A 49.5 percentage point gap in cache hit rate isn't just a technical benchmark — it's a cost multiplier that compounds with every session, every user, and every agent you run in production.
To make it concrete: a financial services firm running 50 concurrent MemGPT agents for client advisory workflows, each handling 20 turns per session at ~16,000 tokens of context, wastes roughly 56% of every prefill computation with prefix caching. With substring caching, that waste drops to ~6.6%. At enterprise scale, the GPU hours saved translate directly to infrastructure budget. The pattern repeats across any stateful agent workload:
- Customer support agents that remember full account history across sessions
- Legal or compliance research assistants with large, repeatedly-retrieved document sets
- Financial advisory bots maintaining client context across dozens of interactions
- Knowledge management systems where the same internal documents are retrieved repeatedly
The rule of thumb for infrastructure teams:
Prefix caching is sufficient for standard RAG with a fixed system prompt, batch inference with shared prompt prefixes, and stateless chatbots without persistent memory.
Non-prefix caching is required for memory-augmented agents like MemGPT, multi-turn sessions with dynamic working context, long-running workflows with archival retrieval, RAG, and any agent where prompt structure shifts across turns.
As agentic AI matures and enterprises move from stateless chatbots to stateful, memory-augmented agents, the caching strategy you choose will increasingly determine whether your AI deployment is economically sustainable.
How Tensormesh Is Adressing This
Tensormesh was built specifically for the caching and routing challenges that emerge in production AI inference — including exactly this problem.
Our intelligent caching layer implements prefix caching natively, and will be soon adding non-prefix caching integrating directly with vLLM, SGLang, and most of Hugging Face's 300,000+ model library. For MemGPT and similar memory-augmented agent architectures, this would mean:
- Sub-second latency maintained even across long multi-turn sessions with large archival contexts
- 5–10x GPU cost reduction compared to naive inference, driven by high cache reuse rates
- No changes required to your existing MemGPT implementation — caching operates at the serving layer
Visit https://www.tensormesh.ai/ to get started.
Conclusion
MemGPT's memory management paradigm — dynamic Working Context, shifting FIFO Queue, variable archival retrievals — is what makes it powerful for enterprise use cases requiring persistent agent memory. It's also what makes prefix caching fail as an optimization strategy.
The content most worth caching (archival documents, function definitions, recalled conversations) is exactly what prefix caching can't reach, because it sits downstream of the parts of the prompt that keep changing. Non-prefix caching resolves this by matching on content rather than position, enabling ~93.4% cache hit rates vs. ~43.9%, dramatically reduced prefill latency, and GPU economics that scale as your agent workloads grow.
For enterprises deploying memory-augmented LLM agents at scale, choosing the right caching strategy isn't an infrastructure detail — it's a business decision that determines whether the economics work.
References

